Three ways to model the same ETL task in SSIS. One takes 10 minutes and is straightforward. One takes hours, 40 Data Flow Tasks, and won’t survive the next requirements change. The question “how much SQL belongs in an SSIS package?” decides maintainability, readability, and development speed — not tool loyalty.
What you’ll take away:
- Three approaches to a real hierarchy/ranking task on
[DimEmployee]from AdventureWorks (Stored Procedure, OLE-DB Source Task, pure SSIS tasks). - Evaluation along five dimensions: development time, readability, maintainability, performance, functionality.
- Strategic context “ETL 2026”: where SSIS still fits and where modernisation alternatives (Azure Data Factory, dbt, Airflow, Postgres native tooling, Talend Open Studio) work better today.
- Take-away and FAQ with the four most common SSIS-vs.-SQL questions at the end.
Prerequisites: SQL Server 2017+ and SSIS 2017+ (Visual Studio with SSDT), AdventureWorksDW2017 as the sample database. The argument carries over to current SSIS versions (2019/2022) and to Postgres with modern ETL tooling.
Note on the screenshots: The screenshots still show the historical table naming (
[dbo].[post00210001]…) and alternative ranking axes in Solution 3 (HireDate/BirthDateinstead ofVacationHours/SickLeaveHours) — the prose and code samples use the modernised naming.
Contents
- How this article started
- The three approaches
- Evaluation
- ETL 2026 — how much SQL belongs in an SSIS package today?
- Take-away
- FAQ
- Related articles
How this article started
SQL Server Integration Services (SSIS) is a powerful tool set for building ETL pipelines. There are plenty of good reasons to use SSIS — and plenty against. If we stay within the Microsoft product stack, the alternative for complex ETL pipelines is (essentially) Transact-SQL (T-SQL).
This article is part of a series of articles on the important decision criteria for choosing the right technology — SSIS and/or T-SQL.
With source control in mind, I have shown in the article SSIS vs. SQL: Source Code Management the advantages of SQL scripts (specifically SQL Server Stored Procedures) over SSIS. Changes to a stored procedure are easy to inspect by comparing two versions in Visual Studio. A similar comparison of two versions of an SSIS package shows a confusing number of changes in the underlying .dtsx document type, even for minor modifications — making it virtually impossible to identify what actually changed between versions.
In that article I used a T-SQL statement to derive the hierarchy levels of employees from the table [AdventureWorksDW2017].[DimEmployee], and then computed a ranking of vacation hours and sick leave hours across levels 1 to 5. The ranking was supposed to use the windowed functions NTILE() and DENSE_RANK(). The NTILE classification was supposed to produce three classes.
Solving this task in T-SQL took just a few minutes. Common Table Expressions (CTE) support recursive calls, and the ranking was quickly built with the windowed functions.
To compare T-SQL procedures/scripts against SSIS packages with respect to source control, I wanted to build an “equivalent” SSIS package. I naively assumed this would take a bit more time but would still be solvable with reasonable effort.
Way off!
For the two key requirements there is, to my knowledge, no simple solution — let alone standard tasks or functions that could be used in an Expression:
- Recursive determination of hierarchy levels
- Calculation of the ranking
A simple approach for the recursive hierarchy-level determination was nowhere to be found in the usual blog posts, and I couldn’t derive one on the fly either. I quickly gave up on computing the NTILE() ranking through Expressions and ended up implementing that part of the task in Script Tasks. The result is — given the complexity of the artefact — reasonably clean, but it is a static solution limited to five hierarchy levels.
Along the way the question kept popping up: why didn’t you just put the relevant SQL statement into the OLE-DB Source Task — how much SQL would that be?
In this article, three approaches are described and compared with this question in mind:
- Solution 1 — Complex SQL in a Stored Procedure. A stored procedure runs a SELECT statement and writes the result into a target table. The procedure is invoked from an Execute SQL Task in the SSIS control flow. One control flow, nothing else.
- Solution 2 — Complex SQL in a Data Source Task. The SQL statement can instead live in the Data Source Task of an SSIS Data Flow, followed by a Destination Task that writes the data into the target table. The solution contains one control flow, one data flow, and two Data Flow Tasks.
- Solution 3 — Simple SQL in a Data Source Task. The extreme alternative without SQL (other than a trivial SELECT in the Data Source Task) uses a “temporary” table for intermediate results, one control flow, two data flows, and many Data Flow Tasks, connected by non-trivial Conditional Splits and Precedence Constraints.
These three alternatives are evaluated along the following dimensions:
- Development time
- Readability
- Maintainability
- Performance
- Functionality
The three approaches
The three solutions are introduced below. All of them were developed with Microsoft Visual Studio 2017 and SQL Server 2017.
Solution 1 — Complex SQL in a Stored Procedure
This solution is based on a complex SQL statement that writes data into the target table [dbo].[fct_employee_hierarchy_ranking]. At its core is the recursive use of a Common Table Expression (CTE) to compute the hierarchy levels. The statement is preceded by a TRUNCATE TABLE to empty the target table before the INSERT. The procedure is named [dbo].[sp_insert_employee_hierarchy_ranking] and is invoked via an Execute SQL Task in the SSIS control flow.
1: CREATE OR ALTER PROCEDURE [dbo].[sp_insert_employee_hierarchy_ranking]
2: AS
3: BEGIN
4: SET NOCOUNT ON;
5:
6: TRUNCATE TABLE [dbo].[fct_employee_hierarchy_ranking];
7:
8: WITH CTE_Employee AS
9: (
10: -- Anchor of the recursive CTE: the CEO as the top-level employee
11: -- with no manager. [Level] = 1 marks the root of the hierarchy.
12: SELECT
13: [EmployeeKey]
14: ,[FirstName]
15: ,[LastName]
16: ,[Title]
17: ,[ParentEmployeeKey]
18: ,[VacationHours]
19: ,[SickLeaveHours]
20: ,1 AS [Level]
21: FROM
22: [AdventureWorksDW2017].[dbo].[DimEmployee]
23: WHERE
24: [ParentEmployeeKey] IS NULL
25:
26: UNION ALL
27:
28: -- Recursive step: every employee whose [ParentEmployeeKey] points
29: -- to an employee already in the CTE. [Level] is incremented by 1
30: -- per depth. UNION ALL is the only recursion-permitted set
31: -- operation between anchor and recursive member.
32: SELECT
33: T01.[EmployeeKey]
34: ,T01.[FirstName]
35: ,T01.[LastName]
36: ,T01.[Title]
37: ,T01.[ParentEmployeeKey]
38: ,T01.[VacationHours]
39: ,T01.[SickLeaveHours]
40: ,T00.[Level] + 1 AS [Level]
41: FROM
42: [AdventureWorksDW2017].[dbo].[DimEmployee] AS T01
43: INNER JOIN
44: CTE_Employee AS T00
45: ON
46: T01.[ParentEmployeeKey] = T00.[EmployeeKey]
47: WHERE
48: T01.[Status] = N'Current'
49: )
50: INSERT INTO [dbo].[fct_employee_hierarchy_ranking]
51: (
52: [ParentEmployeeKey]
53: ,[EmployeeKey]
54: ,[LastName]
55: ,[FirstName]
56: ,[Title]
57: ,[Level]
58: ,[VacationHours]
59: ,[SickLeaveHours]
60: ,[VacationHours_NTILE]
61: ,[VacationHours_DENSE_RANK]
62: ,[SickLeaveHours_NTILE]
63: ,[SickLeaveHours_DENSE_RANK]
64: )
65: SELECT
66: [ParentEmployeeKey]
67: ,[EmployeeKey]
68: ,[LastName]
69: ,[FirstName]
70: ,[Title]
71: ,[Level]
72: ,[VacationHours]
73: ,[SickLeaveHours]
74: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_NTILE]
75: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_DENSE_RANK]
76: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_NTILE]
77: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_DENSE_RANK]
78: FROM
79: CTE_Employee;
80: END;
81: GOThe recursive CTE produces the [Level] value for every employee. The subsequent INSERT … SELECT computes the NTILE and DENSE_RANK values per hierarchy level — separated by [VacationHours] and [SickLeaveHours]. SQL Server delivers both as window functions directly out of the statement.
Solution 2 — Complex SQL in a Data Source Task
The second solution relies on an SSIS Data Flow that contains nothing but an OLE-DB Source Task and an OLE-DB Destination Task.
The OLE-DB Source Task defines the data source as a SQL statement — the same complex statement from procedure [dbo].[sp_insert_employee_hierarchy_ranking], but without the INSERT INTO part. The data stream is written to the target table by the downstream OLE-DB Destination Task.
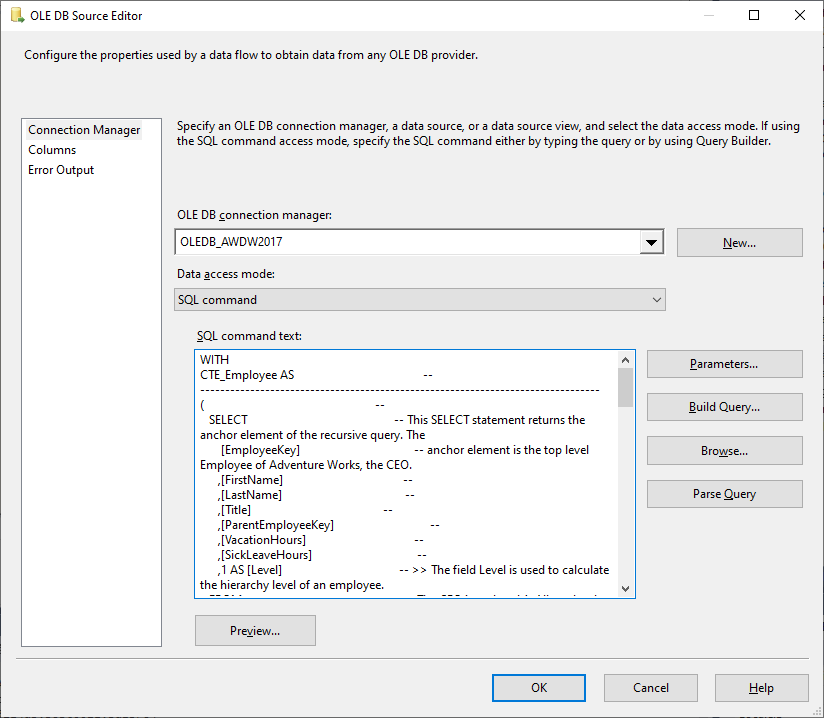
No further transformations are carried out in the data flow.
Solution 3 — Simple SQL in a Data Source Task
The third solution uses SSIS tasks exclusively for computing the hierarchy levels and the ranking. The chosen solution comprises one control flow, two data flows, and two tables. The control flow contains two SQL Tasks and two Data Flow Tasks with the following responsibilities:
- 0500 SQL Truncate Table. This task truncates the two tables required by the solution:
[dbo].[stg_employee_levels](staging for the computed hierarchy levels) and[dbo].[fct_employee_hierarchy_ranking](target fact table). - 1000 DFT Calculate Levels. This data flow computes the hierarchy level for every employee. The calculation is not generic — it is limited to the five existing hierarchy levels.
- 2000 SQL Level Counts. Computing the ranking via the windowed function
NTILE()requires knowing the number of employees per hierarchy level. This SQL Task runs five SELECT statements to count employees per level and stores the results in dedicated variables. - 3000 DFT Calculate Ranking. The second data flow computes the ranking using Script Tasks and writes the final result to the target table
[dbo].[fct_employee_hierarchy_ranking].
Control Flow
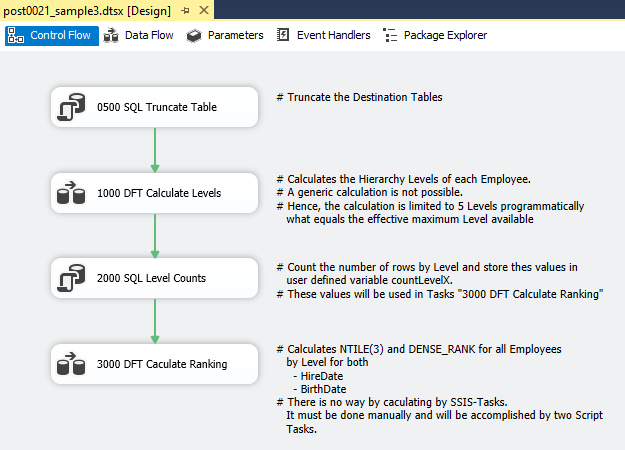
1000 DFT Calculate Levels
The data source 1000 OLEDB Source holds a simple SQL statement with no further calculations.
![Configuration of the OLE-DB Source Task 1000 OLEDB Source in Solution 3: a lean SELECT against [DimEmployee] with eight columns and the initialisation [Level] = 1, no window functions and no recursion.](https://sql.marcus-belz.de/wp-content/uploads/2020/05/post00210007.png)
3000 DFT Calculate Ranking
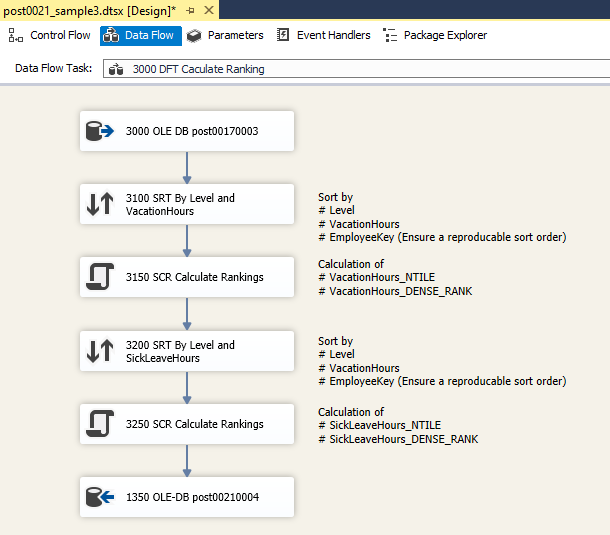
Evaluation
Development time
| Solution 1 | Solution 2 | Solution 3 | Verdict |
|---|---|---|---|
| A few minutes | A few minutes | Several hours | T-SQL clearly ahead |
Complex SQL in a Stored Procedure
As mentioned above, the development had two challenges: determining the hierarchy levels of employees and computing the ranking. T-SQL offers concepts and constructs for both that make implementation straightforward and fast. Hierarchically structured data is easy to query using a recursive Common Table Expression. The windowed functions NTILE() and DENSE_RANK() handle the second challenge in a few lines. The SQL statement was built in just a few minutes.
Complex SQL in a Data Source Task
The second solution uses the same complex SQL statement as the data source in an OLE-DB Source Task. The SSIS package contains only two Data Flow Tasks: one data source and one data destination. No further transformations are needed. The bulk of the effort goes into writing the SQL statement — which, as explained above, is a matter of minutes. The SSIS package itself is built with minimal effort.
Simple SQL in a Data Source Task
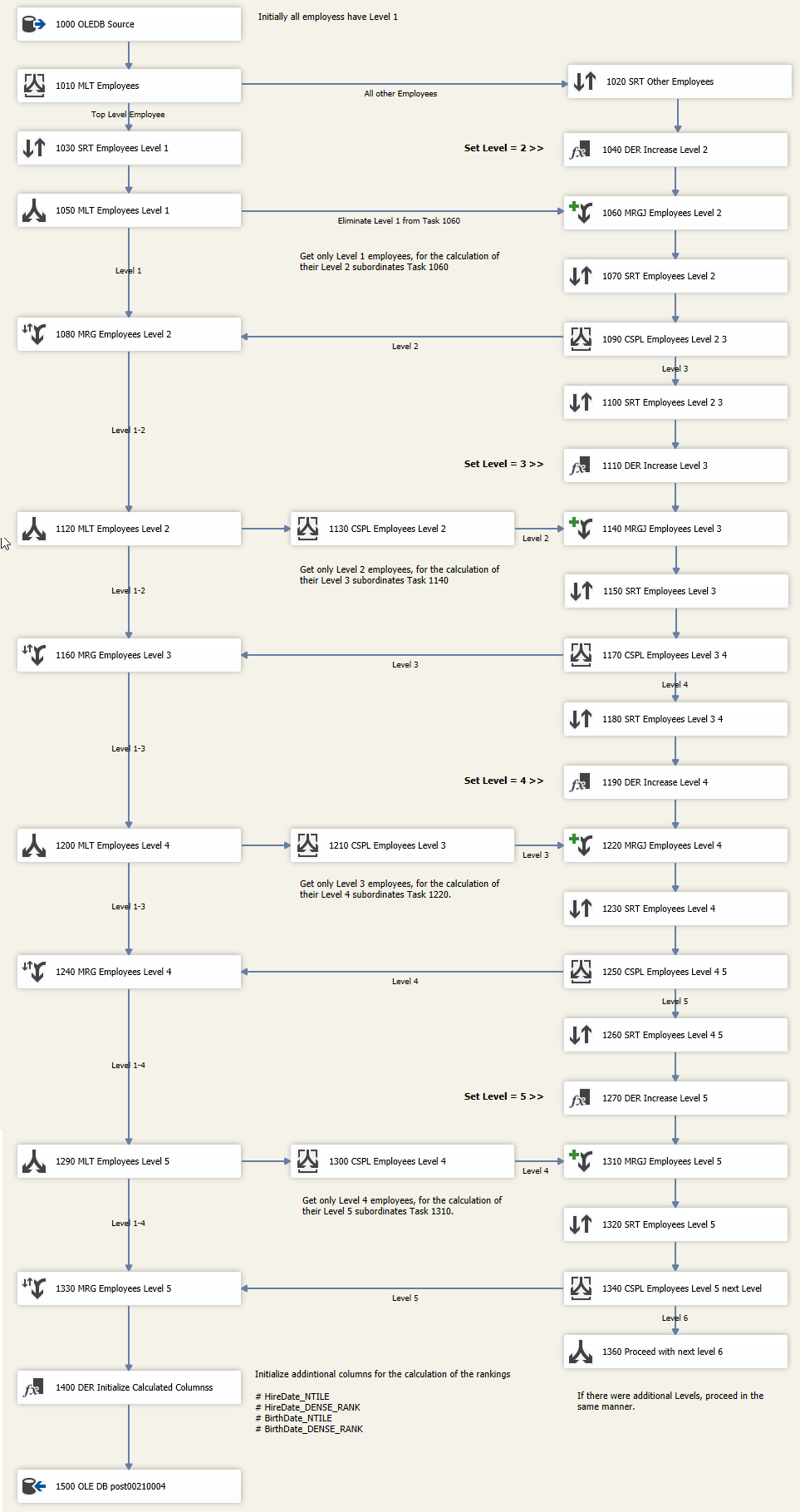
This solution was developed under the constraint that both the hierarchy level calculation and the ranking had to be implemented using SSIS native tasks. The data source is defined by a simple SELECT statement; all further transformations live in SSIS Data Flow Tasks. Unlike T-SQL, there is no single ideal solution path here. Going into this example I assumed naively that both challenges could be solved in SSIS just as comfortably as in T-SQL. They cannot — at least not by my current understanding. For the non-generic hierarchy-level determination and the ranking calculation, more than 40 Data Flow Tasks were configured and linked with complex Precedence Constraints and Join/Split Tasks. Development took several hours.
Summary
In this example, the requirements are implemented much faster in T-SQL than in (only) SSIS. Where T-SQL all but dictates the solution path, the SSIS approach had to be designed from scratch. The effort to write the SQL statement was a fraction of what the SSIS solution required.
The more SQL is in an SSIS package, the faster development becomes.
Readability
| Solution 1 | Solution 2 | Solution 3 | Verdict |
|---|---|---|---|
| Great in SSMS editor | Hard inside the OLE-DB “peephole” | Tedious — 40+ tasks to inspect | T-SQL clearly ahead |
Complex SQL in a Stored Procedure
The actual SQL INSERT statement of the first solution spans roughly 80 lines when generously structured. With reasonable formatting on top, the chosen solution is quickly grasped. The statement above is easy to read.
Complex SQL in a Data Source Task
The second solution reuses parts of the SQL statement from the stored procedure [dbo].[sp_insert_employee_hierarchy_ranking] of the first solution. While the statement itself is easy to understand, it is hard to read inside the SQL command text field of the OLE-DB Source Task. The field uses a proportional font, and on top of that it is little more than a peephole. Complex statements are very hard to read through this dialog.
Simple SQL in a Data Source Task
In the SSIS-based third solution, a simple SQL statement defines the data source. The complexity lives in the 40+ Data Flow Tasks. While a SQL statement can be read more or less top-to-bottom, reading a complex SSIS package requires significant action: every task must be opened, its configuration inspected. A large part of the logic lives in Precedence Constraints and Join Tasks and has to be worked out. Grasping the logic of this solution is considerably more effort than reading the complex SQL statement.
Summary
Well-structured and well-formatted T-SQL statements are vastly more readable than SSIS packages that perform the same task.
The degree of readability also depends on where the SQL statement is stored and in which “editor” the statement is displayed by default. A procedure or statement is highly readable in SQL Server Management Studio, but not in the dialog of the OLE-DB Source Task.
Maintainability
| Solution 1 | Solution 2 | Solution 3 | Verdict |
|---|---|---|---|
| SP diff readable, versionable | SQL hidden in .dtsx | .dtsx diff effectively unreadable | T-SQL clearly ahead; SSIS only wins on provider switches |
Readability
If maintainability is measured by readability, the point clearly goes to T-SQL as well. Both the locations to change and those where new functionality is added can be identified quickly in a SQL script.
Future requirements
Maintainability is fundamentally about future changes — and here a few aspects make a simple assessment harder.
The number of hierarchy levels in the dimension [AdventureWorksDW2017].[DimEmployee] is effectively limited to five. A future change to six levels would mean no additional effort for Solution 1 (complex statement). No matter how deep the hierarchy is structured, T-SQL handles it — within the technical limit of 32,767 recursions inside a recursive Common Table Expression.
Things look very different when SSIS does most of the heavy lifting. Extending it by additional hierarchy levels means a substantial change to the SSIS package. The extra effort can be dramatically high when a complex SSIS data flow has to be modified somewhere in the middle — possibly forcing every downstream Data Flow Task to be redeveloped from scratch.
The assessment can flip if the driver for future change is a switch of the database provider. Moving the database management system from, say, SQL Server to Oracle offers no guarantee that the SQL dialect used in your statements is supported on the new platform. In the worst case, a statement cannot be migrated — or only with substantial effort — to the new environment. For Solution 3 a platform change means — provided that the new database provider is supported by SSIS — no functional change to the SSIS package.
Comparing two versions of an artefact
A prerequisite for building maintainable artefacts is versioning them in source control. For every shipped and deployed version of a piece of software or an ETL pipeline, the developer must be able to identify the corresponding code in the repository. In case of a defect, code changes must be traceable in order to identify root causes. Which version introduced the buggy implementation? What changed between versions? Comparing two versions of an artefact usually leads to an answer quickly. I have walked through the comparability aspects of T-SQL statements and SSIS packages in the article SSIS vs. SQL: Source Code Management. Two versions of an SSIS package are, plain and simple, not comparable. From that angle, SSIS packages are very hard to maintain.
Summary
Most developers offload a large share of transformations to SQL statements inside Data Source Tasks. Hardly anyone wants to develop a complex statement that joins multiple tables through an SSIS data flow — the effort would be exorbitant and (let’s leave it at that) the performance abysmal. From a maintainability standpoint, then, the next question is fair: why is the statement placed inside the Data Flow Source Task in the first place?! Wouldn’t it be better to wrap it in a View, a Stored Function, or a Stored Procedure? In that case, the View, Stored Function, or Stored Procedure can be quickly transferred via a Visual Studio database project and a Schema Compare into a SQL script that is checked into source control.
When weighing SQL against SSIS along maintainability, here too the verdict comes out clearly in favour of SQL.
One small exception: when future changes are driven by infrastructure shifts (a different database provider, a distributed environment, etc.), the trade-offs of both technologies need to be weighed in detail.
Performance
| Solution 1 | Solution 2 | Solution 3 | Verdict |
|---|---|---|---|
| Engine-native, fast | Similar to Solution 1 | Roughly 2× slower | T-SQL for synchronous workloads; SSIS for async/file-heavy |
Many factors influence performance and would need to be taken into account in a robust comparison. For the sake of simplicity I do not account for these factors here — instead I use the execution times I measured to back up my conviction with a broad brush: SSIS is slower than T-SQL whenever an SSIS package contains even simple transformations that could just as easily be expressed as a SQL statement.
A basic example is the simple joining of tables. In SSIS, a data stream must be sorted before it can be used in a Join Task. Sorting kills the asynchronous processing of the stream. The synchronous data processing of a join in SSIS is without doubt slower than processing it inside a SQL statement in SQL Server.
The Solution 3 (SSIS only) presented in this article is roughly twice as slow as Solution 1 (SQL only). I am aware that this is an extremely undifferentiated statement.
For completeness it should be mentioned that there are tasks SSIS handles substantially better than a SQL statement.
Summary
As a broad-brush statement: complex transformations implemented in SSIS only are slower than a pure SQL implementation.
Functionality
| Solution 1 | Solution 2 | Solution 3 | Verdict |
|---|---|---|---|
| Full engine feature set | Same as Solution 1 | Full SSIS flexibility (sources, parallelism) | T-SQL for SQL-solvable tasks; SSIS for non-SQL (Fuzzy, files) |
This article deals with a task that — among other things — strikingly shows how differently the chosen technologies perform. What can be solved with a relatively simple SQL statement here requires a fairly complex approach in SSIS. This is not meant as a fundamental plea for T-SQL. There are plenty of requirements that cannot be solved with T-SQL — or at least not as easily. SSIS is far more flexible regarding data sources, parallelisation, file operations, and many other aspects.
Summary
If a task can be solved with T-SQL, it can and should be solved with T-SQL. In all other cases, SSIS is the appropriate tool.
ETL 2026 — how much SQL belongs in an SSIS package today?
The core question of this article — how much SQL belongs in an ETL pipeline, how much in the engine — is no longer a pure SQL-Server question in 2026. The Microsoft stack is one option among others, and the answer “more SQL is better” carries over to all modern stacks. Three perspectives on the tool landscape that shape the maintainability argument today.
The Microsoft stack today
SQL Server Integration Services is still officially supported (SQL Server 2022 ships SSIS in the Standard and Enterprise editions, though advanced adapters — Oracle, Teradata, SAP BW, Fuzzy Lookup — are Enterprise-only) but is no longer the focus of active investment. Major innovation has shifted to the cloud counterparts: Azure Data Factory and Synapse Pipelines offer the same drag-and-drop paradigms with added cloud-native connectors (Blob Storage, Cosmos DB, Snowflake, Databricks). Anyone migrating an SSIS stack to Azure can keep running existing packages via SSIS Integration Runtime inside ADF — a migration path, not an end-of-life.
The maintainability question from this article transfers 1:1: in ADF/Synapse, too, a Copy Data activity with an embedded SQL statement is more readable than a nested pipeline graph with 20+ Mapping Data Flow steps. The tool changes; the architectural question stays.
The Postgres world
There is no direct SSIS counterpart on the Postgres side — the world there is more open and more SQL-centric. Three building blocks shape the architecture:
Database native tooling. COPY for bulk loads from CSV/JSON, INSERT ... ON CONFLICT for upserts, RETURNING for chaining. For the example in this article, a single Postgres statement is enough — recursive CTE, NTILE, and DENSE_RANK have been built-ins since Postgres 8.4:
1: WITH RECURSIVE cte_employee AS
2: (
3: SELECT
4: employee_key AS employee_key
5: ,parent_employee_key AS parent_employee_key
6: ,vacation_hours AS vacation_hours
7: ,sick_leave_hours AS sick_leave_hours
8: ,1 AS hierarchy_level
9: FROM
10: public.dim_employee
11: WHERE
12: parent_employee_key IS NULL
13:
14: UNION ALL
15:
16: SELECT
17: T01.employee_key
18: ,T01.parent_employee_key
19: ,T01.vacation_hours
20: ,T01.sick_leave_hours
21: ,T02.hierarchy_level + 1
22: FROM
23: public.dim_employee AS T01
24: INNER JOIN cte_employee AS T02
25: ON
26: T01.parent_employee_key = T02.employee_key
27: WHERE
28: T01.status = 'Current'
29: )
30: INSERT INTO public.fct_employee_hierarchy_ranking
31: SELECT
32: employee_key
33: ,hierarchy_level
34: ,vacation_hours
35: ,sick_leave_hours
36: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key)
37: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key)
38: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key)
39: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key)
40: FROM
41: cte_employee;
Same language constructs as in Solution 1, the same single statement, just idiomatic snake_case and no [bracket] quoting.
dbt as the transform layer. dbt (“data build tool”) is SQL-centric: each model is a .sql file holding a SELECT, and the materialisation (table, view, incremental, snapshot) is steered by a config directive. The same statement as a dbt model:
1: {{ config(materialized = 'table') }}
2:
3: WITH RECURSIVE cte_employee AS
4: (
5: SELECT
6: employee_key
7: ,parent_employee_key
8: ,vacation_hours
9: ,sick_leave_hours
10: ,1 AS hierarchy_level
11: FROM
12: {{ ref('dim_employee') }}
13: WHERE
14: parent_employee_key IS NULL
15:
16: UNION ALL
17:
18: SELECT
19: e.employee_key
20: ,e.parent_employee_key
21: ,e.vacation_hours
22: ,e.sick_leave_hours
23: ,c.hierarchy_level + 1
24: FROM
25: {{ ref('dim_employee') }} AS e
26: INNER JOIN cte_employee AS c
27: ON
28: e.parent_employee_key = c.employee_key
29: WHERE
30: e.status = 'Current'
31: )
32: SELECT
33: employee_key
34: ,hierarchy_level
35: ,vacation_hours
36: ,sick_leave_hours
37: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key) AS vacation_hours_ntile
38: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key) AS vacation_hours_dense_rank
39: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key) AS sick_leave_hours_ntile
40: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key) AS sick_leave_hours_dense_rank
41: FROM
42: cte_employee;
dbt turns this file into a runnable CREATE TABLE plus INSERT, handles schema management, builds a DAG over all models from the {{ ref() }} references, and delivers versionable diffs — the same maintainability lever as a stored procedure, just stack-agnostic (Postgres, Snowflake, BigQuery, Redshift, Databricks).
Orchestration. Airflow, Prefect, and Dagster are the common schedulers for Postgres/dbt pipelines — each task runs SQL statements; the engine stays the database. The SSIS-typical “data stream flows through the pipeline” semantics is deliberately absent; for analytical workloads it is considered an anti-pattern (row-by-row processing does not scale).
Talend Open Studio. Anyone looking for a true SSIS counterpart on the Postgres side — drag-and-drop editor, job-centric, platform-neutral — ends up at Talend Open Studio. Qlik acquired Talend in 2023 and discontinued the free Open Studio variant in 2024; active maintenance only exists in community forks (maintenance status uncertain). For new projects, Talend Open Studio is no longer a future-proof path; existing Talend jobs are migration candidates toward dbt + Airflow or the commercial Talend cloud platform.
The question remains: how much SQL?
No matter the stack — SSIS, ADF, dbt, Airflow, Talend — the maintainability punchline doesn’t move: the statement belongs in the database when the database can execute it efficiently. The ETL engine is an orchestrator, not a compute engine. dbt at its core is “SQL as code”, Airflow DAGs invoke SQL snippets, ADF Copy Data activities are at their most performant when they delegate the transformation to the SQL engine instead of crunching it inside a Mapping Data Flow.
The article’s original question — “how much SSIS do you really want?” — translates into the modern tool stack as “how much ETL engine do you really want?”. The answer remains: as little as possible, as much as needed.
Take-away
- When the database can execute the statement efficiently, the statement belongs in the database — not in the ETL engine. This is the strategic architectural decision, not a matter of taste.
- SSIS packages with 40+ Data Flow Tasks are maintainability debt, not a feature. Every future requirements change will cost more than it has to.
- Version control is a maintainability criterion. Stored-procedure diffs are readable;
.dtsxdiffs are not. Hiding ETL logic in the engine destroys auditability. - The tool question (SSIS, ADF, Talend, dbt, Airflow) is secondary. The SQL-vs.-engine split is the decision that matters; the specific tool is an implementation detail.
FAQ
Stored Procedure — almost always. A procedure is visible in the database repository, can be versioned, transferred into a Visual Studio database project via Schema Compare, and edited comfortably in SQL Server Management Studio. The SQL statement in the SQL command text field of the OLE-DB Source Task disappears into the .dtsx package — no syntax highlighting, no sensible diff between versions, no direct access from other applications.
Three common triggers: (1) the pipeline already runs mostly on SQL statements — dbt formalises that into a transform layer without touching the SQL substance; (2) the orchestration requirements outgrow SSIS native capabilities (retry logic, backfill, external triggers, parallel scheduling across many pipelines) — Airflow, Prefect, or Dagster are a better answer here than SSIS Sequence Containers; (3) the stack needs to become cloud- and multi-database-ready — SSIS is SQL-Server-centric, dbt and Airflow are dialect-agnostic.
.dtsx package meaningfully? Pragmatically: you don’t. .dtsx files are XML, but the XML diff is muddied by GUID reorderings and position properties. Workable approaches: (1) BIDS Helper / SSDT diff extension for Visual Studio shows a structural-tree diff instead of an XML diff; (2) screenshot diff of the Control Flow and Data Flow designers; (3) accompanying SQL scripts offloaded into stored procedures, so the content diff lives in a versionable SQL script and the .dtsx only handles orchestration. Option 3 is the strategic answer and the actual point of this article.
As a single statement — see the “The Postgres world” section above. A recursive CTE for the hierarchy levels, NTILE and DENSE_RANK as window functions per level, written into a target table via INSERT INTO ... SELECT. Postgres has all three constructs natively; an SSIS-like drag-and-drop layer isn’t needed at all.
Plain T-SQL with synchronous data processing in the same database — typically 2 to 5 times faster, because the database engine can use the optimiser, parallel plans, and memory-resident operators, while SSIS drags the data row-by-row through the Data Flow. SSIS wins for asynchronous processing (writing data while more is still being read), for cross-database operations without a linked server, and for file-centric pipelines (bulk-insert from 50 CSV files with schema detection). So the question “SSIS or T-SQL” is less about performance and more about architecture.
Related articles
SSIS-vs.-SQL cluster:
- SSIS vs. SQL — the cluster root with the overarching tool discussion.
- SSIS vs. SQL: Impersonation — sister article on the
EXECUTE ASpattern. - SSIS vs. SQL: Source Code Management — the versioning argument of this article in detail.
ETL context:
- Data quality in an ETL process — data quality building blocks that need to be added to each of the three solutions.
- Design Pattern // Logging an ETL process with T-SQL — a logging pattern that amplifies the
.dtsxdiff advantage of SQL even further.