Drei Wege, dieselbe ETL-Aufgabe in SSIS abzubilden. Einer braucht 10 Minuten und ist nachvollziehbar. Einer braucht Stunden, 40 Data Flow Tasks und überlebt die nächste Anforderungs-Änderung nicht. Die Frage „wie viel SQL gehört in ein SSIS-Paket?“ entscheidet über Wartbarkeit, Lesbarkeit und Entwicklungs-Tempo — nicht über Tool-Loyalität.
Was dich erwartet:
- Drei Lösungs-Ansätze für eine reale Hierarchie-/Ranking-Aufgabe auf
[DimEmployee]aus AdventureWorks (Stored Procedure, OLE-DB Source Task, Pure-SSIS-Tasks). - Bewertung entlang fünf Dimensionen: Entwicklungs-Dauer, Lesbarkeit, Wartbarkeit, Performance, Funktionsumfang.
- Strategische Einordnung „ETL 2026″: wo SSIS noch passt und wo Modernisierungs-Alternativen (Azure Data Factory, dbt, Airflow, Postgres-Bordmittel, Talend Open Studio) heute besser greifen.
- Take-Away und FAQ mit den vier häufigsten SSIS-vs.-SQL-Fragen am Ende.
Voraussetzung: SQL Server 2017+ und SSIS 2017+ (Visual Studio mit SSDT), AdventureWorksDW2017 als Sample-Datenbank. Die Argumentation überträgt sich sinngemäß auf aktuelle SSIS-Versionen (2019/2022) und auf Postgres mit modernen ETL-Tools.
Hinweis zu den Screenshots: Die Bildschirmfotos zeigen noch die historische Tabellen-Nomenklatur (
[dbo].[post00210001]…) und alternative Ranking-Achsen in Lösung 3 (HireDate/BirthDatestattVacationHours/SickLeaveHours) — im Fließtext und in den Code-Beispielen ist die Nomenklatur auf sprechende Namen modernisiert.
Inhalt
- Die Vorgeschichte zu diesem Artikel
- Die drei Lösungsansätze
- Bewertung
- ETL 2026 — wie viel SQL gehört heute in ein SSIS-Paket?
- Take-Away
- FAQ
- Verwandte Artikel
Die Vorgeschichte zu diesem Artikel
Die Vorgeschichte zu diesem Artikel
SQL Server Integration Services (SSIS) ist ein äußerst mächtiges Tool Set für die Entwicklung von ETL-Strecken. Es gibt viele gute Gründe, die für einen Einsatz von SSIS sprechen. Es gibt derer aber auch genügend, die dagegen sprechen. Beschränken wir uns auf den Microsoft Produkt Stack, dann kommt als Alternative für die Entwicklung von komplexen ETL Strecken (im Wesentlichen) nur noch Transact-SQL (T-SQL) in Frage.
Dieser Artikel gehört zu einer Serie von Artikeln, die wichtige Entscheidungskriterien für die Wahl der richtigen Technologie(n) — SSIS und/oder T-SQL — beleuchten.
Mit Blick auf die Verwendung einer Quellcodeverwaltung habe ich in dem Artikel SSIS vs. Transact-SQL: Quellcodeverwaltung die Vorteile von SQL-Skripten (und hier SQL Server Stored Procedures) gegenüber SSIS herausgestellt. Die Änderungen in einer Stored Procedure lassen sich leicht durch Vergleich zweier Versionen in Visual Studio darstellen. Ein ähnlicher Vergleich zweier Versionen eines SSIS-Pakets zeigt selbst bei minimalen Änderungen bereits eine unübersichtliche Anzahl an Änderungen im zugrundeliegenden Dokumententyp .dtsx — damit scheint es schier unmöglich, die Änderung zweier Versionen zu identifizieren.
In dem erwähnten Artikel habe ich über ein T-SQL-Statement die Hierarchie-Ebenen der Mitarbeiter aus der Tabelle [AdventureWorksDW2017].[DimEmployee] abgeleitet, um anschließend auf der Basis der gefundenen Hierarchie-Ebenen 1 bis 5 ein Ranking der Urlaubs- und Krankheitsstunden zu ermitteln. Die Ermittlung sollte jeweils über die Windowed Functions NTILE() und DENSE_RANK() erfolgen. Die Klassifizierung der Mitarbeiter über die NTILE-Funktion sollte drei Klassen ergeben.
Die Bearbeitung der Aufgabe mit T-SQL hat nur wenige Minuten gedauert. Common Table Expressions (CTE) unterstützen rekursive Aufrufe, und das Ranking ließ sich schnell über die Windowed Functions ermitteln.
Um die Verwendung von T-SQL Prozeduren/Skripten mit Blick auf die Quellcodeverwaltung der Verwendung von SSIS Paketen gegenüberstellen zu können, wollte ich ein “inhaltsgleiches” SSIS Paket entwickeln. Ich habe mich der naiven Vorstellung hingegeben, dass diese Aufgabe zwar mit etwas mehr zeitlichem Aufwand zu lösen ist, aber immerhin mit einem vertretbaren Aufwand lösbar ist.
Weit gefehlt!
Für die beiden wesentlichen Anforderungen gibt es meines Wissens keine einfache Lösung, geschweige denn Standard Tasks oder Funktionen, die in einer Expression verwendet werden könnten.
- Rekursive Ermittlung der Hierarchie-Ebenen
- Ermittlung des Rankings
Einen einfachen Lösungsweg für die rekursive Ermittlung der Hierarchie-Ebenen habe ich weder in den Untiefen einschlägiger Blogs gefunden noch selbst auf die Schnelle ableiten können. Versuche, das Ranking gemäß der Funktion NTILE() über eine Expression zu ermitteln, habe ich schnell aufgegeben und diesen Teil der Aufgabe schließlich über Skript-Tasks gelöst. Das Ergebnis ist — trotz der Komplexität des entwickelten Artefakts — wie ich finde recht übersichtlich. Es ist aber eine statische Lösung und auf fünf Hierarchie-Ebenen beschränkt.
Zwischendurch blitzte dann immer wieder die Frage auf: Warum hast du das relevante SQL-Statement nicht in die OLE-DB Source Task gepackt — wie viel SQL darf’s denn sein?
In diesem Artikel werden drei Lösungsansätze mit Blick auf diese Fragestellung beschrieben und verglichen:
- Lösung 1 — Komplexes SQL in einer Stored Procedure. Ausgangspunkt ist eine Stored Procedure, die das Ergebnis eines SELECT-Statements in eine Ziel-Tabelle schreibt. Die Stored Procedure wird von einer Execute SQL Task im Control Flow eines SSIS-Pakets aufgerufen. Ein Control Flow, sonst nichts.
- Lösung 2 — Komplexes SQL in einer Data Source Task. Das SQL-Statement kann alternativ auch in der Data Source Task eines SSIS Data Flows platziert werden, gefolgt von einer Destination Task, um die Daten in die Ziel-Tabelle zu schreiben. Die Lösung enthält einen Control Flow, einen Data Flow und zwei Data Flow Tasks.
- Lösung 3 — Einfaches SQL in einer Data Source Task. Die extreme Alternative ohne SQL (außer einem einfachen SELECT in der Data Source Task) hat in der von mir entwickelten Variante eine „temporäre“ Tabelle zum Zwischenspeichern des Ergebnisses, einen Control Flow, zwei Data Flows und zahlreiche Data Flow Tasks, die darüber hinaus mit nicht ganz einfachen Conditional Splits und Precedence Constraints verknüpft sind.
Diese drei Alternativen werden in diesem Artikel unter den folgenden Gesichtspunkten bewertet:
- Dauer der Entwicklung
- Lesbarkeit
- Wartbarkeit
- Performance
- Funktionsumfang
Die drei Lösungsansätze
Zunächst werden die drei Lösungen vorgestellt. Alle Lösungen wurden mit Microsoft Visual Studio 2017 und SQL Server 2017 entwickelt.
Lösung 1 — Komplexes SQL in einer Stored Procedure
Diese Lösung basiert auf einem komplexen SQL-Statement, das die Daten in die Zieltabelle [dbo].[fct_employee_hierarchy_ranking] schreibt. Basis des Statements ist die rekursive Verwendung einer Common Table Expression (CTE) für die Berechnung der Hierarchie-Ebenen. Dem Statement vorangestellt ist eine TRUNCATE TABLE-Anweisung, um die Zieltabelle vor dem INSERT zu leeren. Die Prozedur trägt den Namen [dbo].[sp_insert_employee_hierarchy_ranking] und wird in SSIS über eine Execute SQL Task im Control Flow aufgerufen.
1: CREATE OR ALTER PROCEDURE [dbo].[sp_insert_employee_hierarchy_ranking]
2: AS
3: BEGIN
4: SET NOCOUNT ON;
5:
6: TRUNCATE TABLE [dbo].[fct_employee_hierarchy_ranking];
7:
8: WITH CTE_Employee AS
9: (
10: -- Anker der rekursiven CTE: der CEO als Top-Level-Mitarbeiter ohne
11: -- Vorgesetzten. [Level] = 1 markiert die Wurzel der Hierarchie.
12: SELECT
13: [EmployeeKey]
14: ,[FirstName]
15: ,[LastName]
16: ,[Title]
17: ,[ParentEmployeeKey]
18: ,[VacationHours]
19: ,[SickLeaveHours]
20: ,1 AS [Level]
21: FROM
22: [AdventureWorksDW2017].[dbo].[DimEmployee]
23: WHERE
24: [ParentEmployeeKey] IS NULL
25:
26: UNION ALL
27:
28: -- Rekursionsschritt: alle Mitarbeiter, deren [ParentEmployeeKey] auf
29: -- einen bereits in der CTE enthaltenen Mitarbeiter zeigt. [Level] wird
30: -- pro Tiefe um 1 erhöht. UNION ALL ist die einzige rekursions-erlaubte
31: -- Mengenoperation zwischen Anker und rekursivem Glied.
32: SELECT
33: T01.[EmployeeKey]
34: ,T01.[FirstName]
35: ,T01.[LastName]
36: ,T01.[Title]
37: ,T01.[ParentEmployeeKey]
38: ,T01.[VacationHours]
39: ,T01.[SickLeaveHours]
40: ,T00.[Level] + 1 AS [Level]
41: FROM
42: [AdventureWorksDW2017].[dbo].[DimEmployee] AS T01
43: INNER JOIN
44: CTE_Employee AS T00
45: ON
46: T01.[ParentEmployeeKey] = T00.[EmployeeKey]
47: WHERE
48: T01.[Status] = N'Current'
49: )
50: INSERT INTO [dbo].[fct_employee_hierarchy_ranking]
51: (
52: [ParentEmployeeKey]
53: ,[EmployeeKey]
54: ,[LastName]
55: ,[FirstName]
56: ,[Title]
57: ,[Level]
58: ,[VacationHours]
59: ,[SickLeaveHours]
60: ,[VacationHours_NTILE]
61: ,[VacationHours_DENSE_RANK]
62: ,[SickLeaveHours_NTILE]
63: ,[SickLeaveHours_DENSE_RANK]
64: )
65: SELECT
66: [ParentEmployeeKey]
67: ,[EmployeeKey]
68: ,[LastName]
69: ,[FirstName]
70: ,[Title]
71: ,[Level]
72: ,[VacationHours]
73: ,[SickLeaveHours]
74: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_NTILE]
75: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_DENSE_RANK]
76: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_NTILE]
77: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_DENSE_RANK]
78: FROM
79: CTE_Employee;
80: END;
81: GO
Die rekursive CTE erzeugt für jeden Mitarbeiter den [Level]-Wert. Über das anschließende INSERT … SELECT werden die NTILE- und DENSE_RANK-Werte pro Hierarchie-Ebene berechnet — getrennt nach [VacationHours] und [SickLeaveHours]. SQL Server liefert beides als Window Function direkt aus dem Statement.
Lösung 2 — Komplexes SQL in einer Data Source Task
Die zweite Lösung basiert auf einem SSIS Data Flow, der nichts anderes enthält als eine OLE-DB Source Task sowie eine OLE-DB Destination Task.
Die OLE-DB Source Task definiert die Datenquelle als SQL-Statement — eben das oben erwähnte komplexe Statement aus der Prozedur [dbo].[sp_insert_employee_hierarchy_ranking], jedoch ohne den INSERT INTO-Part. Der Datenstrom wird durch die nachgelagerte OLE-DB Destination Task in die Zieltabelle geschrieben.
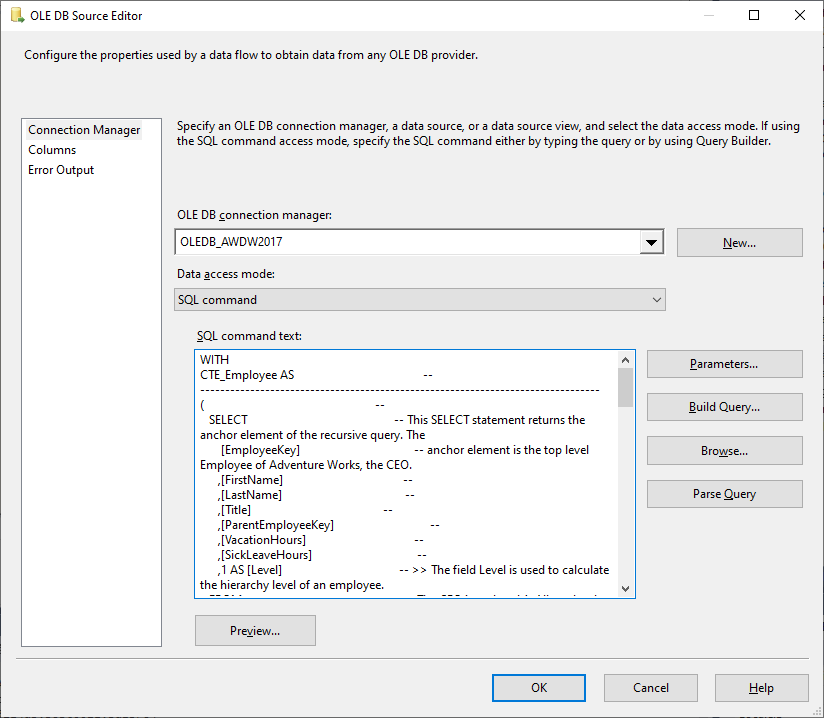
Es werden keine weiteren Transformationen in dem Data Flow durchgeführt.
Lösung 3 — Einfaches SQL in einer Data Source Task
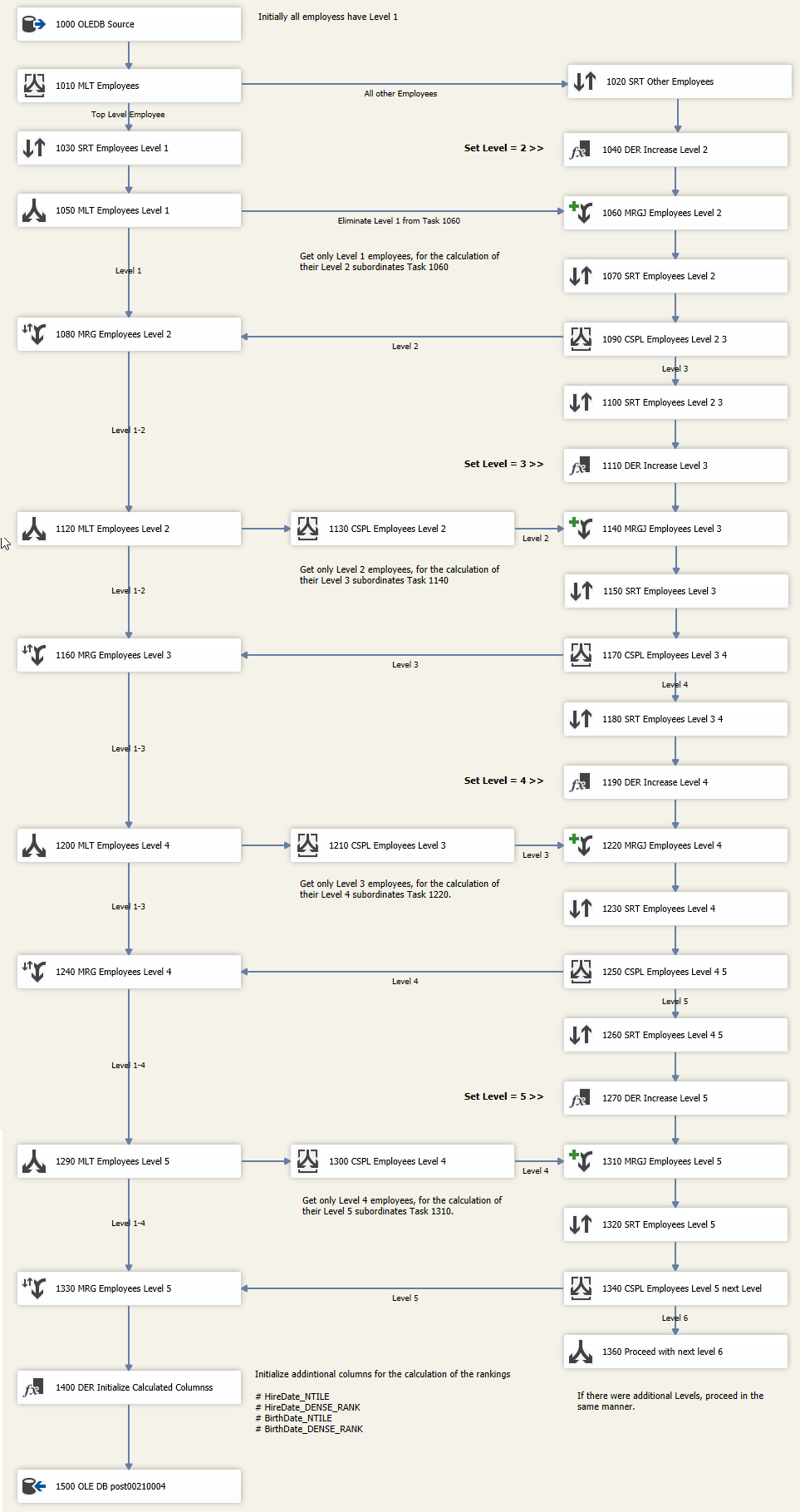
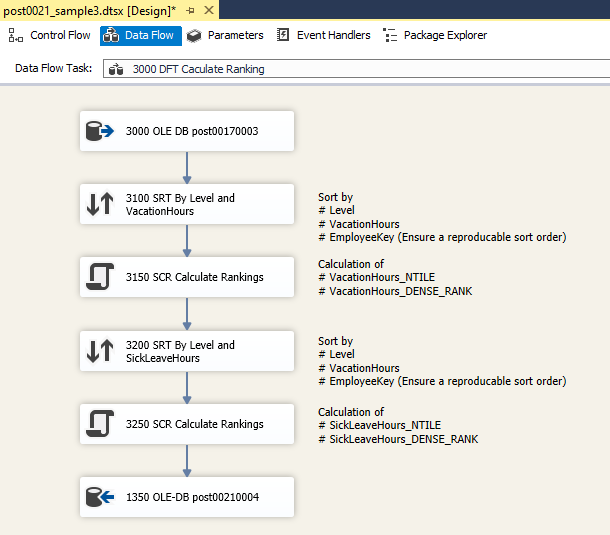
Die dritte Lösung verwendet ausschließlich SSIS Tasks für die Berechnung der Hierarchie-Ebenen sowie des Rankings. Die gewählte Lösung beinhaltet einen Control Flow, zwei Data Flows und zwei Tabellen. Der Control Flow enthält zwei SQL Tasks sowie zwei Data Flow Tasks mit den folgenden Aufgaben:
- 0500 SQL Truncate Table. Diese Task löscht die beiden Tabellen, die für die Lösung benötigt werden:
[dbo].[stg_employee_levels](Staging für die berechneten Hierarchie-Ebenen) und[dbo].[fct_employee_hierarchy_ranking](Ziel-Fakten-Tabelle). - 1000 DFT Calculate Levels. Dieser Data Flow berechnet zu jedem Mitarbeiter den Hierarchie-Level. Die Berechnung ist nicht generisch und auf die fünf vorhandenen Hierarchie-Level begrenzt.
- 2000 SQL Level Counts. Für die Berechnung des Rankings gemäß der Windowed Function
NTILE()ist es erforderlich, die Anzahl der Mitarbeiter je Hierarchie-Level zu kennen. Diese SQL Task führt fünf SELECT-Statements aus, um die Anzahl der Mitarbeiter je Level zu ermitteln und in hierfür vorgesehenen Variablen zu speichern. - 3000 DFT Calculate Ranking. Der zweite Data Flow ermittelt schließlich das Ranking mit Hilfe von Skript-Tasks und speichert das Endergebnis in der Zieltabelle
[dbo].[fct_employee_hierarchy_ranking].
Control Flow
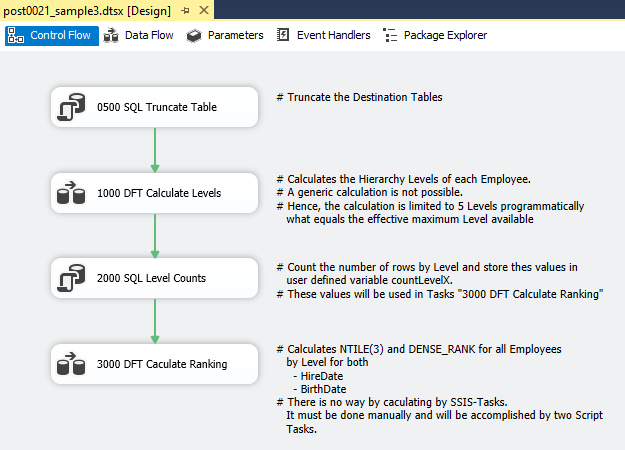
1000 DFT Calculate Levels
Die Datenquelle 1000 OLEDB Source enthält ein einfaches SQL-Statement ohne weitere Berechnungen.
![Konfiguration der OLE-DB Source Task 1000 OLEDB Source in Lösung 3: ein schlankes SELECT auf [DimEmployee] mit acht Spalten und der Initialisierung [Level] = 1, ohne Window Functions und ohne Rekursion.](https://sql.marcus-belz.de/wp-content/uploads/2020/05/post00210007.png)
3000 DFT Calculate Ranking
Bewertung
Dauer der Entwicklung
| Lösung 1 | Lösung 2 | Lösung 3 | Bewertung |
|---|---|---|---|
| Wenige Minuten | Wenige Minuten | Mehrere Stunden | T-SQL klar im Vorteil |
Komplexes SQL in einer Stored Procedure
Bei der Entwicklung gab es — wie oben erwähnt — zwei Herausforderungen: die Ermittlung der Hierarchie-Ebenen der Mitarbeiter und die Ermittlung des Rankings. T-SQL bietet für beide Herausforderungen Konzepte und Lösungen an, die eine einfache und schnelle Umsetzung ermöglichen. Über das Konzept der rekursiven Common Table Expression können hierarchisch organisierte Daten schnell und mit wenig Aufwand abgefragt werden. Mit den Windowed Functions NTILE() und DENSE_RANK() ist auch die zweite Herausforderung mit nur wenigen Zeilen umgesetzt. Das SQL-Statement ist in nur wenigen Minuten erstellt.
Komplexes SQL in einer Data Source Task
Die zweite Lösung verwendet das Komplexe SQL Statement als Datenquelle in einer Data Source Task. Das SSIS Paket der zweiten Lösung enthält lediglich zwei Data Flow Tasks: Eine Datenquelle und ein Datenziel. Es werden keine weiteren Transformationen durchgeführt. Der wesentliche Aufwand ergibt sich aus der Erstellung des SQL Statements. Wie im vorigen Abschnitt erläutert, ist dieses in nur wenigen Minuten erstellt. Das SSIS Paket selbst ist mit nur minimalem Aufwand ebenfalls schnell erstellt.
Einfaches SQL in einer Data Source Task
Diese Lösung wurde unter der Maßgabe entwickelt, dass sowohl die Berechnung der Hierarchie-Ebenen sowie des Rankings mit den Board-Mitteln von SSIS umzusetzen sind. Die Datenquelle der Data Source Task wird durch ein einfaches SELECT Statement definiert. Alle weiteren Transformationen erfolgen über SSIS Data Flow Tasks. Im Unterschied zu T-SQL gibt es hier nicht die eine ideale Lösung. Tatsächlich bin ich vor der Erstellung dieser Beispiel-Lösung dem Trugschluss aufgesessen, dass die beiden Herausforderungen ähnlich komfortabel in SSIS zu lösen sind. Nach meinem derzeitigen Kenntnisstand ist das nicht möglich. Für die nicht generische Ermittlung der Hierarchie-Ebenen und die Ermittlung des Rankings wurden mehr als 40 Data Flow Tasks konfiguriert, die darüber hinaus mit komplexen Precedence-Constraints und Join/Split-Tasks verbunden sind. Die Entwicklung hat einige Stunden Zeit gekostet.
Fazit
In diesem Beispiel sind die Anforderungen mit T-SQL wesentlich schneller umgesetzt als mit (nur) SSIS. Während in T-SQL der Lösungsweg mehr oder weniger vorgegeben ist, musste der Lösungsweg in SSIS erst einmal entworfen werden. Der Aufwand der Entwicklung des SQL Statements entsprach nur einem Bruchteil der Zeit, die für die SSIS Lösung aufgewendet werden musste.
Je mehr SQL in einem SSIS Paket enthalten ist, desto schneller wird die Entwicklung sein.
Lesbarkeit
| Lösung 1 | Lösung 2 | Lösung 3 | Bewertung |
|---|---|---|---|
| Gut im SSMS-Editor | Schwer im OLE-DB-„Guckloch“ | Aufwändig — 40+ Tasks zu sichten | T-SQL klar im Vorteil |
Komplexes SQL in einer Stored Procedure
Das eigentliche SQL INSERT Statement der ersten Lösung erstreckt sich bei großzügiger Strukturierung gerade mal über ca. 80 Zeilen. Sofern das Statement zusätzlich halbwegs ordentlich formatiert ist, ist der gewählte Lösungsweg schnell erfassbar. Das oben abgebildete Statement der ersten Lösung ist gut lesbar.
Komplexes SQL in einer Data Source Task
Die zweite Lösung verwendet in Teilen das SQL-Statement aus der Stored Procedure [dbo].[sp_insert_employee_hierarchy_ranking] der ersten Lösung. Während das Statement an sich gut verständlich ist, ist es innerhalb des Feldes SQL command text der Data Source Task nur schwer lesbar. Zum einen wird für die Darstellung eine proportionale Schriftart verwendet, zum anderen ist das Feld nichts anderes als ein Guckloch. Komplexe Statements sind über diesen Dialog nur sehr schwer lesbar.
Einfaches SQL in einer Data Source Task
In dem auf SSIS basierenden dritten Lösungsansatz wurde als Datenquelle für die Lösung ein einfaches SQL Statement definiert. Die Komplexität liegt hier in den über 40 Data Flow Tasks. Während ein SQL Statement mehr oder minder von oben nach unten gelesen werden kann, sind bei der Lektüre eines komplexen SSIS Paketes umfangreiche Aktionen erforderlich: Alle Tasks sind zu öffnen, ihre Konfiguration muss geprüft werden. Ein großer Teil der Logik ist über die Precedence Constraints und Join Tasks abgebildet und muss erarbeitet werden. Die Erfassung der Logik dieser Lösung ist mit ungleich mehr Aufwand verbunden als die Erfassung des komplexen SQL Statements.
Fazit
T-SQL Statements sind bei strukturierter und formatierter Notation ungleich lesbarer als SSIS Pakete, die die gleiche Aufgabe erfüllen.
Der Grad der Lesbarkeit richtet sich auch danach, wo das SQL Statement gespeichert und in welchem „Editor“ das Statement per Default angezeigt wird. Während eine Prozedur oder eine Statement in SQL Server Management Studio gut lesbar ist, ist es das in dem Dialog der Data Source Task nicht.
Wartbarkeit
| Lösung 1 | Lösung 2 | Lösung 3 | Bewertung |
|---|---|---|---|
| SP-Diff lesbar, versioniert | SQL versteckt im .dtsx | .dtsx-Diff faktisch unlesbar | T-SQL klar im Vorteil; SSIS gewinnt nur bei Provider-Wechsel |
Lesbarkeit
Sofern bei Wartbarkeit auf die Lesbarkeit abgestellt wird, geht dieser Punkt ganz klar ebenfalls an T-SQL. Jene Stellen, die zu ändern sind, aber auch solche, an denen neue Funktionen bereitgestellt werden, können in einem SQL Skript schnell identifiziert werden.
Künftige Anforderungen
Wartbarkeit stellt prinzipiell auf künftige Änderungen ab. Hier gibt es durchaus Aspekte, die eine einfache Bewertung schwierig machen.
Faktisch ist die Anzahl der Hierarchie-Ebenen in der Dimension [AdventureWorksDW2017].[DimEmployee] auf fünf beschränkt. Eine künftige Änderung auf sechs Hierarchie-Ebenen bedeutet für die Lösung 1 (komplexes Statement) keinen zusätzlichen Aufwand. Egal wie tief die Hierarchie strukturiert ist, T-SQL kommt damit zurecht — unter Berücksichtigung der technischen Beschränkung auf 32.767 Rekursionen innerhalb einer rekursiven Common Table Expression.
Anders sieht es bei Verwendung von vorwiegend SSIS aus. Eine Erweiterung um zusätzliche Hierarchie-Ebenen bedeutet hier einen nicht unerheblichen Mehraufwand für die Anpassung des SSIS Paketes. Dramatisch hoch kann der Mehraufwand sein, wenn ein komplexer SSIS Data Flow irgendwo in der Mitte geändert werden muss. Das kann zur Folge haben, dass jene Data Flow Tasks, die der Änderung folgen, komplett neu entwickelt werden müssen.
Auf der anderen Seite kann die Bewertung auch ganz anders ausfallen, wenn der Grund für eine künftige Änderung der Wechsel des Datenbank Providers ist. Bei einem Wechsel des Datenbank Managements Systems von zum Beispiel SQL Server nach Oracle ist nicht gewährleistet, dass der in SQL Statements verwendete Sprachumfang von der künftigen Plattform unterstützt wird. Im schlechtesten Fall kann ein Statement nicht oder nur mit umfangreichem Aufwand an den Sprachumfang der neuen Umgebung angepasst werden. Eine künftige Änderung der Plattform bedeutet für die Lösung 3 – unter der Voraussetzung, dass der Datenbank-Provider von SSIS unterstützt wird – keine Notwendigkeit einer funktionalen Änderung des SSIS Paketes.
Vergleich von zwei Versionen eines Artefaktes
Eine Voraussetzung für die Entwicklung wartbarer Artefakte ist die Versionierung der Artefakte in einer Quellcodeverwaltung. Der Entwickler muss zu jeder ausgelieferten und installierten Version einer Software oder einer ETL-Strecke in der Lage sein, den Code im Repository zu identifizieren. Im Fehlerfall sind Änderungen am Code zurückzuverfolgen, um Fehler identifizieren zu können. Mit welcher Version ist eine fehlerhafte Implementierung erfolgt? Was wurde von Version zu Version geändert? Der Vergleich von jeweils zwei Versionen eines Artefakts führt in der Regel schnell zu einer Antwort. In dem Artikel SSIS vs. Transact-SQL: Quellcodeverwaltung habe ich bereits die Aspekte der Vergleichbarkeit von T-SQL-Statements und SSIS-Paketen herausgearbeitet. Zwei Versionen eines SSIS-Pakets sind schlicht nicht vergleichbar. SSIS-Pakete sind unter diesem Gesichtspunkt nur sehr schwer wartbar.
Fazit
Die meisten Entwickler lagern einen großen Teil von Transformation bereits als SQL Statements in Data Source Tasks aus. Kaum eine Entwicklerin wird ein komplexes Statement, das mehrere Tabellen verjoint, über einen SSIS Data Flow entwickeln wollen. Der Aufwand hierfür wäre vergleichsweise exorbitant hoch und – das sei an dieser Stelle einfach so dahingestellt – die Performance grottig. Unter dem Aspekt der Wartbarkeit sollte dann allerdings die Frage zulässig sein, warum ein Statement innerhalb der Data Flow Source Task platziert wird?! Wäre es nicht besser, das Statement in einer View, einer Stored Function oder einer Stored Procedure zu verpacken? In diesem Fall kann die View, die Stored Function oder die Stored Procedure über ein Visual Studio Datenbank Projekt und einen Schema Compare schnell als SQL Skript in ein Visual Studio Datenbank Projekt überführt werden und das Skript in ein Quellcode Verwaltungssystem eingecheckt werden.
Bei der Bewertung der Vor- und Nachteile von SQL gegenüber SSIS unter dem Gesichtspunkt der Wartbarkeit fällt auch hier die Beurteilung eindeutig zugunsten von SQL aus.
Es gibt eine kleine Ausnahme: Sofern sich künftige Änderungen aus Änderungen der Infrastruktur (anderer Datenbank-Provider, verteilte Umgebung, etc.) ergeben, sind Vor- und Nachteile der beiden Technologien im Detail gegeneinander abzuwägen.
Performance
| Lösung 1 | Lösung 2 | Lösung 3 | Bewertung |
|---|---|---|---|
| Engine-nativ schnell | Ähnlich Lösung 1 | ≈ 2× langsamer | T-SQL bei synchroner Verarbeitung; SSIS bei async/Files |
Es gibt zahlreiche Faktoren, die die Performance beeinflussen können und bei einem belastbaren Vergleich zu berücksichtigen sind. Der Einfachheit halber berücksichtige ich diese Faktoren nicht, um letztlich mit den von mir gemessenen Ausführungszeiten meine Überzeugung pauschal untermauern zu können: SSIS ist langsamer als T-SQL, wenn ein SSIS-Paket bereits einfache Transformationen enthält, die ohne Probleme auch in einem SQL-Statement umgesetzt werden können.
Ein Beispiel hierfür ist bereits das einfache Verjoinen von Tabellen. In SSIS muss ein Datenfluss vor der Verwendung in einer Join Task sortiert werden. Das Sortieren hat zur Folge, dass der Datenfluss nicht mehr asynchron verarbeitet werden kann. Die synchrone Datenverarbeitung eines Joins in SSIS ist ohne Zweifel langsamer als die Verarbeitung innerhalb eines SQL Statements in SQL Server.
Die in diesem Artikel vorgestellte Lösung 3 (nur SSIS) ist im Vergleich zu der Lösung 1 (nur SQL) um den Faktor 2 langsamer. Mir ist bewusst, dass dieses eine äußerst undifferenzierte Aussage ist.
Der Vollständigkeit halber sei allerdings erwähnt, dass es auch Aufgaben gibt, die in SSIS wesentlich besser performen als ein SQL Statement.
Fazit
Pauschal kann die undifferenzierte Aussage getroffen werden, dass komplexe Transformationen, die nur mit SSIS umgesetzt sind, langsamer performen als eine reine SQL Umsetzung.
Funktionsumfang
| Lösung 1 | Lösung 2 | Lösung 3 | Bewertung |
|---|---|---|---|
| Engine-Funktionen voll nutzbar | Wie Lösung 1 | Volle SSIS-Flexibilität (Quellen, Parallelisierung) | T-SQL bei SQL-Lösbarem; SSIS bei Non-SQL (Fuzzy, Files) |
Dieser Artikel behandelt eine Aufgabe, die unter anderem eindrucksvoll aufzeigt, wie unterschiedlich die Leistungsfähigkeit der gewählten Technologien ist. Was in diesem Beispiel mit einem vergleichsweise einfachen SQL Statement gelöst werden kann, erfordert mit SSIS einen eher komplexen Lösungsansatz. Das soll nun wahrlich kein grundsätzliches Plädoyer für T-SQL sein. Es gibt eine Menge Anforderungen, die mit T-SQL nicht oder nicht so einfach lösbar sind. SSIS ist ungleich flexibler bezüglich Datenquellen, Parallelisierung, Dateioperationen und vieler anderer Aspekte.
Fazit
Sofern eine Aufgabe mit T-SQL lösbar ist, kann und sollte diese mit T-SQL bearbeitet werden. In allen anderen Fällen kommt natürlich SSIS zum Zuge.
ETL 2026 — wie viel SQL gehört heute in ein SSIS-Paket?
Die Kernfrage des Artikels — wie viel SQL gehört in eine ETL-Strecke, wie viel in die Engine — ist 2026 keine reine SQL-Server-Frage mehr. Der Microsoft-Stack ist eine Option neben anderen, und die Antwort „mehr SQL ist besser“ überträgt sich auf alle modernen Stacks. Drei Sichten auf die Tool-Landschaft, die die Wartbarkeits-Argumentation heute prägt.
Microsoft-Stack heute
SQL Server Integration Services ist weiter offiziell supported (SQL Server 2022 enthält SSIS in der Standard- und Enterprise-Edition, wobei erweiterte Adapter — Oracle, Teradata, SAP BW, Fuzzy Lookup — Enterprise-only sind), steht aber nicht mehr im aktiven Investment-Fokus. Größere Neuerungen kommen seit Jahren hauptsächlich für die Cloud-Pendants: Azure Data Factory und Synapse Pipelines liefern dieselben Drag-&-Drop-Paradigmen, ergänzt um Cloud-native Konnektoren (Blob Storage, Cosmos DB, Snowflake, Databricks). Wer einen SSIS-Stack auf Azure migriert, kann bestehende Pakete via SSIS Integration Runtime in ADF weiterbetreiben — Migrationspfad, kein End-of-Life.
Die Wartbarkeits-Frage aus diesem Artikel überträgt sich 1:1: auch in ADF/Synapse ist eine Copy Data-Activity mit eingebettetem SQL-Statement lesbarer als ein verschachtelter Pipeline-Graph mit 20+ Mapping-Data-Flow-Steps. Das Tool wechselt, die Architektur-Frage bleibt.
Postgres-Welt
Auf Postgres-Seite gibt es kein direktes SSIS-Pendant — die Welt ist offener und SQL-zentrierter. Drei Bausteine prägen die Architektur:
Bordmittel der Datenbank. COPY für Bulk-Loads aus CSV/JSON, INSERT ... ON CONFLICT für Upserts, RETURNING für Kettung. Für das Beispiel dieses Artikels reicht ein einziges Postgres-Statement — rekursive CTE, NTILE und DENSE_RANK sind Bordmittel seit Postgres 8.4:
1: WITH RECURSIVE cte_employee AS
2: (
3: SELECT
4: employee_key AS employee_key
5: ,parent_employee_key AS parent_employee_key
6: ,vacation_hours AS vacation_hours
7: ,sick_leave_hours AS sick_leave_hours
8: ,1 AS hierarchy_level
9: FROM
10: public.dim_employee
11: WHERE
12: parent_employee_key IS NULL
13:
14: UNION ALL
15:
16: SELECT
17: T01.employee_key
18: ,T01.parent_employee_key
19: ,T01.vacation_hours
20: ,T01.sick_leave_hours
21: ,T02.hierarchy_level + 1
22: FROM
23: public.dim_employee AS T01
24: INNER JOIN cte_employee AS T02
25: ON
26: T01.parent_employee_key = T02.employee_key
27: WHERE
28: T01.status = 'Current'
29: )
30: INSERT INTO public.fct_employee_hierarchy_ranking
31: SELECT
32: employee_key
33: ,hierarchy_level
34: ,vacation_hours
35: ,sick_leave_hours
36: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key)
37: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key)
38: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key)
39: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key)
40: FROM
41: cte_employee;
Derselbe Sprachumfang wie in Lösung 1, dasselbe Single-Statement, nur idiomatisch snake_case und ohne [Bracket]-Quoting.
dbt als Transform-Layer. dbt („data build tool“) ist SQL-zentriert: jedes Modell ist eine .sql-Datei mit einem SELECT, die Materialisierung (Table, View, Incremental, Snapshot) steuert eine Konfig-Direktive. Dasselbe Statement als dbt-Modell:
1: {{ config(materialized = 'table') }}
2:
3: WITH RECURSIVE cte_employee AS
4: (
5: SELECT
6: employee_key
7: ,parent_employee_key
8: ,vacation_hours
9: ,sick_leave_hours
10: ,1 AS hierarchy_level
11: FROM
12: {{ ref('dim_employee') }}
13: WHERE
14: parent_employee_key IS NULL
15:
16: UNION ALL
17:
18: SELECT
19: e.employee_key
20: ,e.parent_employee_key
21: ,e.vacation_hours
22: ,e.sick_leave_hours
23: ,c.hierarchy_level + 1
24: FROM
25: {{ ref('dim_employee') }} AS e
26: INNER JOIN cte_employee AS c
27: ON
28: e.parent_employee_key = c.employee_key
29: WHERE
30: e.status = 'Current'
31: )
32: SELECT
33: employee_key
34: ,hierarchy_level
35: ,vacation_hours
36: ,sick_leave_hours
37: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key) AS vacation_hours_ntile
38: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY vacation_hours, employee_key) AS vacation_hours_dense_rank
39: ,NTILE(3) OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key) AS sick_leave_hours_ntile
40: ,DENSE_RANK() OVER (PARTITION BY hierarchy_level ORDER BY sick_leave_hours, employee_key) AS sick_leave_hours_dense_rank
41: FROM
42: cte_employee;
dbt erzeugt aus der Datei einen lauffähigen CREATE TABLE plus INSERT, übernimmt das Schema-Management, baut einen DAG aller Modelle aus den {{ ref() }}-Verweisen und liefert versionierbare Diffs — derselbe Wartbarkeits-Hebel wie bei einer Stored Procedure, nur stack-übergreifend (Postgres, Snowflake, BigQuery, Redshift, Databricks).
Orchestrierung. Airflow, Prefect und Dagster sind die geläufigen Scheduler für Postgres-/dbt-Pipelines — jeder Task führt SQL-Statements aus, die Engine bleibt die Datenbank. Die SSIS-typische „Datenstrom-läuft-durch-die-Pipeline“-Semantik fehlt bewusst; sie gilt für analytische Workloads als Anti-Pattern (Row-by-Row-Verarbeitung skaliert nicht).
Talend Open Studio. Wer ein echtes SSIS-Pendant auf Postgres-Seite sucht — Drag-&-Drop-Editor, Job-zentriert, plattformneutral — landet bei Talend Open Studio. Qlik hat 2023 Talend übernommen und die kostenfreie Open-Studio-Variante 2024 eingestellt; aktive Pflege gibt es nur noch in Form von Community-Forks (Maintenance-Status unsicher). Für Neuprojekte ist Talend Open Studio damit kein zukunftsfähiger Pfad mehr; bestehende Talend-Jobs sind Migrations-Kandidaten in Richtung dbt + Airflow oder kommerzielle Talend-Cloud-Plattform.
Die Frage bleibt: wie viel SQL?
Egal welcher Stack — SSIS, ADF, dbt, Airflow, Talend — die Wartbarkeits-Pointe ändert sich nicht: das Statement gehört in die Datenbank, wenn die Datenbank es effizient ausführen kann. Die ETL-Engine ist ein Orchestrator, kein Rechen-Engine. dbt ist im Kern „SQL als Code“, Airflow-DAGs rufen SQL-Snippets auf, ADF-Copy Data-Activities sind dann am performantesten, wenn sie die Transformation an die SQL-Engine delegieren statt im Mapping-Data-Flow zu rechnen.
Die ursprüngliche Frage des Artikels — „wie viel SSIS soll es denn sein?“ — überträgt sich in den modernen Tool-Stack als „wie viel ETL-Engine soll es denn sein?“. Die Antwort bleibt: so wenig wie möglich, so viel wie nötig.
Take-Away
- Wenn die Datenbank das Statement effizient ausführen kann, gehört das Statement in die Datenbank — nicht in die ETL-Engine. Das ist die strategische Architektur-Entscheidung, nicht eine Geschmacksfrage.
- SSIS-Pakete mit 40+ Data Flow Tasks sind eine Wartbarkeits-Schuld, kein Feature. Jede künftige Anforderungs-Änderung wird teurer als sie sein müsste.
- Versionskontrolle ist ein Wartbarkeits-Kriterium. Stored-Procedure-Diffs sind lesbar,
.dtsx-Diffs sind es nicht. Wer ETL-Logik in der Engine versteckt, verliert die Audit-Trail-Fähigkeit. - Die Tool-Frage (SSIS, ADF, Talend, dbt, Airflow) ist nachgelagert. Die SQL-vs.-Engine-Aufteilung ist die Entscheidung, die zählt; das konkrete Tool ist Implementierungs-Detail.
FAQ
Stored Procedure — fast immer. Eine Prozedur ist im Datenbank-Repository sichtbar, lässt sich versionieren, durch Schema Compare in ein Visual-Studio-Datenbankprojekt überführen und im SQL Server Management Studio sauber editieren. Das SQL-Statement im SQL command text-Feld der OLE-DB Source Task verschwindet im .dtsx-Paket — kein Syntax-Highlighting, kein vernünftiger Diff zwischen zwei Versionen, kein direkter Zugriff aus anderen Anwendungen.
Drei Trigger sind die üblichen: (1) die Pipeline läuft heute schon mehrheitlich auf SQL-Statements — dbt formalisiert das als Transform-Layer, ohne dass die SQL-Substanz angefasst werden muss; (2) die Orchestrierungs-Anforderungen wachsen über die SSIS-Bordmittel hinaus (Retry-Logik, Backfill, externe Trigger, paralleles Scheduling auf vielen Pipelines) — dann sind Airflow, Prefect oder Dagster eine bessere Antwort als SSIS-Sequence Containers; (3) der Stack soll cloud- und multi-database-fähig werden — SSIS ist SQL-Server-zentrisch, dbt und Airflow sind dialekt-agnostisch.
.dtsx-Pakets sinnvoll? Pragmatisch: gar nicht. .dtsx-Dateien sind XML, das XML-Diff ist aber durch GUID-Reorderings und Position-Properties verrauscht. Praktikable Annäherungen: (1) BIDS Helper / SSDT-Diff-Erweiterung für Visual Studio zeigt einen Strukturbaum-Diff statt XML-Diff; (2) Screenshot-Diff der Control Flow– und Data Flow-Designer; (3) Begleitende SQL-Skripte in Stored Procedures auslagern, sodass der inhaltliche Diff im versionierbaren SQL-Skript stattfindet und das .dtsx nur Orchestrierung enthält. Option 3 ist die strategische Antwort und der eigentliche Punkt dieses Artikels.
Als ein einziges Statement — siehe Sektion „Postgres-Welt“ oben. Rekursive CTE für die Hierarchie-Ebenen, NTILE und DENSE_RANK als Window Functions pro Level, geschrieben in eine Ziel-Tabelle per INSERT INTO ... SELECT. Postgres bietet alle drei Konstrukte nativ; ein SSIS-vergleichbarer Drag-&-Drop-Layer ist gar nicht nötig.
Reines T-SQL bei synchroner Datenverarbeitung in derselben Datenbank — meist um Faktor 2 bis 5 schneller, weil die Datenbank-Engine den Optimizer, parallele Pläne und memory-resident Operatoren nutzen kann, während SSIS die Daten Row-by-Row durch den Data Flow zieht. SSIS gewinnt bei asynchroner Verarbeitung (Daten schreiben, während weitere gelesen werden), bei Cross-Database-Operationen ohne Linked Server und bei datei-zentrierten Pipelines (Bulk-Insert aus 50 CSV-Files mit Schemaerkennung). Die Frage „SSIS oder T-SQL“ ist also weniger Performance- als Architektur-Entscheidung.
Verwandte Artikel
SSIS-vs.-SQL-Cluster:
- SSIS vs. SQL — die Cluster-Wurzel mit der grundsätzlichen Tool-Diskussion.
- SSIS vs. SQL: Identitätswechsel — Schwester-Artikel zum
EXECUTE AS-Pattern. - SSIS vs. SQL: Quellcodeverwaltung — die Versionierungs-Argumentation aus diesem Artikel im Detail.
ETL-Kontext:
- Design Pattern // Architektur eines ETL-Prozesses — Big-Picture für die Strecken-Architektur.
- Datenqualität in einem ETL-Prozess — Datenqualitäts-Bausteine, die in jeder der drei Lösungen ergänzt werden müssen.
- Design Pattern // Protokollierung eines ETL-Prozesses mit SQL — Logging-Pattern, das den
.dtsx-Diff-Vorteil von SQL noch verstärkt.