Zwei Versionen eines SSIS-Pakets diffen — selbst eine triviale Umbenennung erzeugt acht „geänderte Bereiche“ im XML, und der Diff lokalisiert den eigentlichen Edit nicht einmal korrekt. Dieselbe Modifikation in einer Stored Procedure zeigt drei Zeilen Diff, in 30 Sekunden reviewbar. Source-Code-Management ist eine Wartbarkeits-Entscheidung — keine Tool-Frage, sondern eine Artefakt-Format-Frage.
Was dich erwartet:
- Vergleich zweier Versionen eines T-SQL-Skripts in Visual Studio: ein klar lesbarer Inline-Diff.
- Vergleich zweier Versionen eines SSIS-Pakets (
.dtsx): selbst eine Skript-Task-Umbenennung erzeugt acht „geänderte Bereiche“ im XML, mit falscher Diff-Lokalisierung. - Komplexes Beispiel: dieselbe Hierarchie-Ranking-Aufgabe auf
[DimEmployee]aus AdventureWorks — als Stored Procedure versioniert klar diffbar, als SSIS-Paket faktisch nicht. - Versionskontrolle 2026: was sich seit dem 2018er-TFS-Stand bewegt hat — Git, Liquibase/Flyway, sqlmesh.
Voraussetzung: SQL Server 2017+ (für die Beispiele), SSIS 2017+ (Visual Studio mit SSDT), Git oder Azure DevOps Server als VCS. Beispiele 2018 mit Visual Studio 2017 + TFS entwickelt — das Diff-Argument überträgt sich 1:1 auf den 2026er Git-zentrischen Stack.
Inhalt
- Überblick
- Vergleich von zwei Versionen eines SQL-Skriptes
- Vergleich von zwei Versionen eines einfachen SSIS-Paketes
- Vergleich von komplexen Entwicklungsartefakten
- Versionskontrolle 2026
- Take-Away
- FAQ
- Verwandte Artikel
Überblick
SQL Server Integration Services (SSIS) ist ein äußerst mächtiges Tool Set für die Entwicklung von ETL-Strecken. Es gibt viele gute Gründe, die für einen Einsatz von SSIS sprechen. Es gibt derer aber auch genügend, die dagegen sprechen. Beschränken wir uns auf den Microsoft Produkt Stack, dann kommt als Alternative für die Entwicklung von komplexen ETL Strecken (im Wesentlichen) nur noch Transact-SQL (T-SQL) in Frage.
Dieser Artikel gehört zu einer Serie von Artikeln, die wichtige Entscheidungskriterien für die Wahl der richtigen Technologie(n) — SSIS und/oder T-SQL — beleuchten.
Eine Quellcodeverwaltung ermöglicht die Speicherung von Quellcode in verschiedenen Versionen. Nach einer Änderung kann die geänderte Datei als neue Version gespeichert werden. Mit der geänderten Version der Datei werden auch Metadaten wie Datum und Uhrzeit der Änderung, Benutzerkennung der Person die die Änderung durchgeführt hat, Verweis auf einen Change-Request, etc. gespeichert. Ältere Versionen eines Dokumentes können damit wieder hergestellt werden.
Darüber hinaus bieten Quellcodeverwaltungen zusätzliche Features an, die unter anderem für die Arbeit in einem Mehrentwicklerteam und auch für das Releasemanagement unerlässlich sind. Kurz: Die Verwaltung von Quellcode ist essentieller Bestandteil professioneller Softwareentwicklung. Im Microsoft-Umfeld ist heute Git der Standard — entweder als Repo bei GitHub/GitLab/Bitbucket oder als Selbst-Hosting via Azure DevOps Server (der Nachfolger des Team Foundation Servers, TFS). Beide lassen sich in die Entwicklungsumgebung Visual Studio integrieren.
Ein weiteres wichtiges Feature einer Quellcodeverwaltung ist der Vergleich zweier Versionen einer Datei. Über einen Vergleich zweier Versionen der gleichen Datei können die Unterschiede identifiziert werden. Ein Anwendungsfall hierfür ist zum Beispiel das 4-Augen-Prinzip. Ein Entwickler arbeitet an einem Dokument und ein weiterer führt einen Review des geänderten Dokumentes durch. Relevant für den Review sind nur die Änderungen in der neuen Version und diese können über einen Versionsvergleich ermittelt werden.
Der Vergleich von zwei Versionen einer Datei ist allerdings nur dann hilfreich, wenn aus den ermittelten Änderungen die Bedeutung und ggf. der Grund der Änderung ersichtlich sind. Ein Vergleich von Binär-Dateien ist in der Regel nicht hilfreich, da weder die Bedeutung der Änderung noch der Grund erkennbar sind. Bei einem Vergleich von zwei Versionen einer Text-Datei ist die Wahrscheinlichkeit hoch, dass beides erkennbar ist. Etwas schwieriger wird es allerdings auch hier, wenn die Daten in der Text-Datei hierarchisch und strukturiert gespeichert sind. So werden SSIS-Pakete in einer hierarchisch strukturierten Weise in XML-Dateien mit der Extension *.dtsx gespeichert, während SQL Statements üblicherweise als (reine) Text-Dateien mit der Extension *.sql gespeichert werden.
Dieser Artikel beschreibt den Versions-Vergleich von SQL-Skripten und SSIS-Paketen anhand von drei Beispielen.
- Vergleich von zwei Versionen eines SQL Statements
- Vergleich von zwei Versionen eines einfachen SSIS-Paketes
- Vergleich von komplexen Entwicklungsartefakten
Vergleich von zwei Versionen eines SQL-Skriptes
Die folgende Abbildung zeigt das Ergebnis eines Vergleichs von zwei Versionen eines SQL-Skriptes in Visual Studio. In diesem Vergleich werden die Abweichungen farblich hervorgehoben.
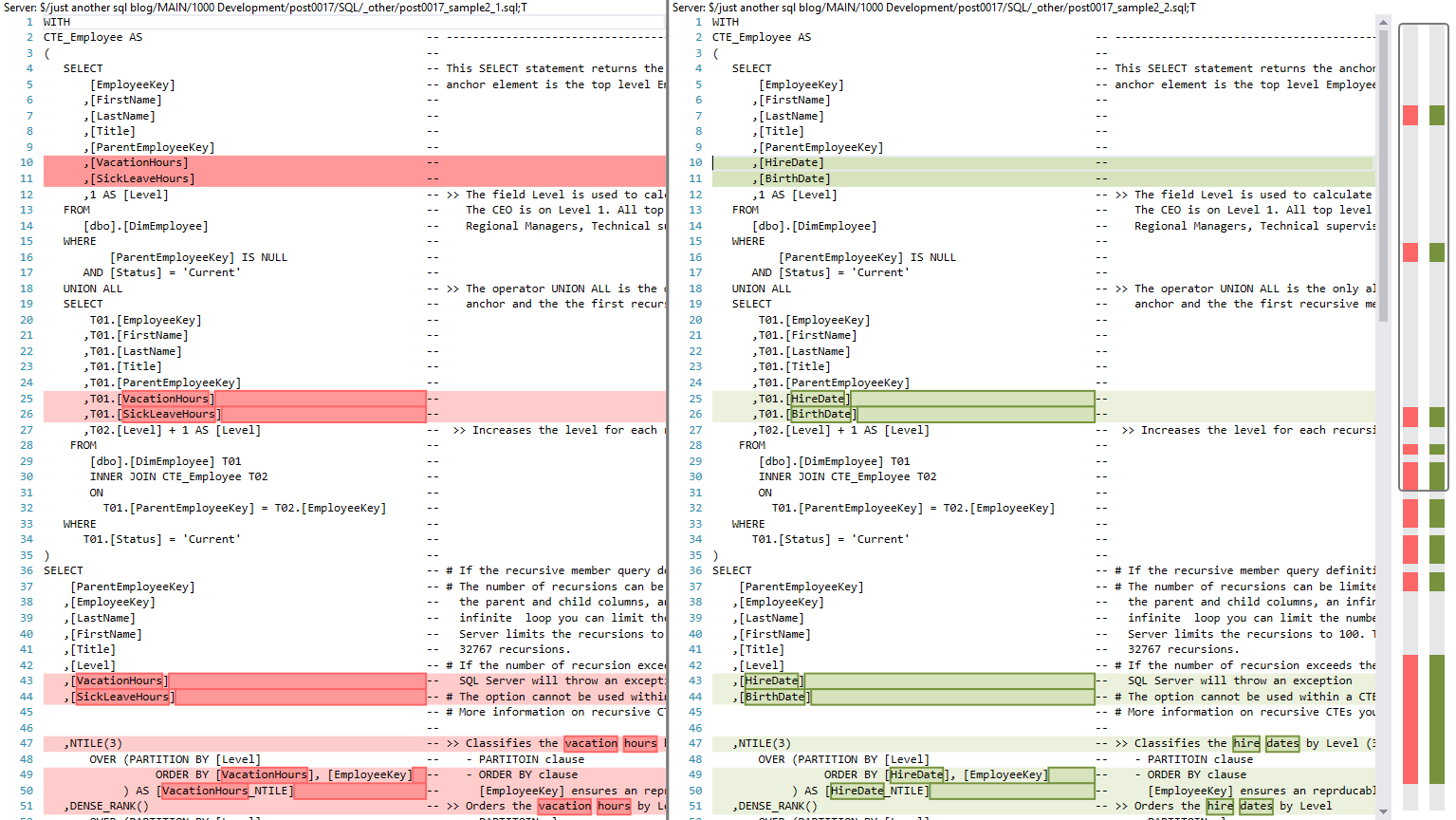
Der Screenshot zeigt auf der linken Seite das SQL Statement vor der Änderung und auf der rechten Seite das geänderte SQL Statement. In dem geänderten SQL Statement sind Zeilen, die eine Änderung enthalten, hellgrün hinterlegt. Änderungen selbst werden in einem kräftigeren Grün hervorgehoben. In der Vorgängerversion auf der linken Seite sind die korrespondierenden Texte in roter Farbe hinterlegt.
Rechts neben dem vertikalen Scroll-Balken sind die geänderten Bereiche in dem gesamten Dokument angedeutet. Eine gute Beschreibung zur Verwendung des Datei-Vergleichs findet sich in der Online-Dokumentation zu Git in Azure DevOps von Microsoft.
Vergleich von zwei Versionen eines einfachen SSIS-Paketes
Die Entwicklung von ETL-Strecken mit SSIS erfolgt in SSIS-Paketen. SSIS-Pakete werden als XML-Dokument gespeichert. Microsoft selbst hat zum SSIS-Paketformat unter anderem ausgeführt:
In der aktuellen Version von Integration Services wurden wichtige Änderungen am Paketformat (DTSX-Datei) vorgenommen, um das Format besser lesbar zu machen und Pakete besser vergleichen zu können. Außerdem wurde das Zusammenführen von Paketen verbessert, die keine miteinander in Konflikt stehenden Änderungen oder im Binärformat gespeicherte Änderungen enthalten.
Dieses Zitat stammt aus der historischen MS-Doku zum SSIS-Paketformat (eine spezifische Seite zur Format-Überarbeitung in SQL Server 2014, inzwischen aus der Live-Doku entfernt); die technische DTSX-Spezifikation lebt als Open Spec MS-DTSX weiter. Demnach wurde das Format weiterentwickelt, um unter anderem Pakete besser vergleichen zu können.
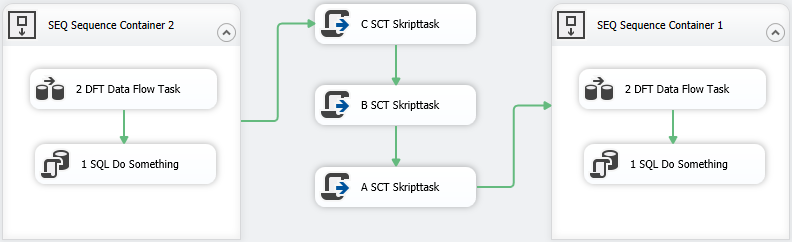
Die folgenden beiden Screenshots zeigen zwei Versionen eines Control Flows eines SSIS-Paketes, in dem lediglich der Name der zweiten Skript-Task von B SCT Skripttask nach D SCT Skripttask geändert wurde. Die Screenshots wurden von einem SSIS-Paket genommen, in dem Tasks einfach in dem Control Flow platziert, beliebig benannt, miteinander verbunden aber nicht weiter konfiguriert. Das Beispiel ist ein einfaches und daher nur plakatives Beispiel.
Version 1
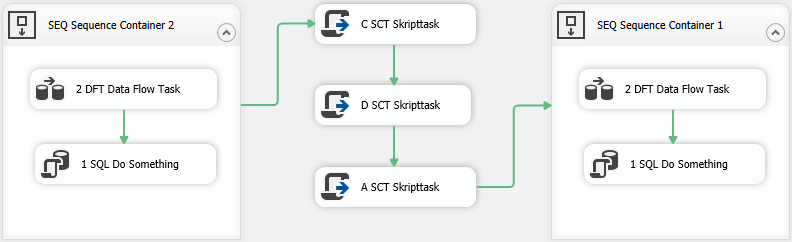
Version 2
Versionsvergleich
Der Vergleich beider Versionen bringt Erstaunliches zu Tage. Die Änderung des Namens einer Skript-Task resultiert in sagenhaften 8 geänderten Bereichen des SSIS-Paketes/XML-Dokumentes, die rechts neben der vertikalen Scroll-Bar angezeigt werden.

Die Zeilen 60 bis 77 repräsentieren (unter anderem) die Skripttask B SCT Skripttask in der Vorgänger-Version. Diese Skripttask wurde gemäß Vergleich nach C SCT Skripttask umbenannt und nicht nach D SCT Skripttask. Die Zeilen 78 bis 95 repräsentieren (unter anderem) die Skripttask C SCT Skripttask in der Vorgänger-Version. Diese Skripttask wurde laut Vergleich nach D SCT Skripttask umbenannt.
Noch mal zur Erinnerung: Geändert wurde lediglich der Name der Skripttask B SCT Skripttask nach D SCT Skripttask.
Der Vergleich liefert hier schlicht ein falsches Ergebnis.
Vergleich von komplexen Entwicklungsartefakten
In diesem Abschnitt wird ein etwas komplexeres Beispiel betrachtet, das in einer ähnlichen Form durchaus in der Praxis zu finden sein könnte.
Aufgabe
In diesem Beispiel ist das Ranking der Mitarbeiter in der Tabelle [AdventureWorksDW2017].[DimEmployee] je Hierarchie-Stufe entlang der Urlaubszeiten sowie Krankheitszeiten der Mitarbeiter zu ermitteln. Zu jedem Mitarbeiter sind vier Kennzahlen zu ermitteln. Für die Berechnung der Kennzahlen ist die Methodologie der bei den Kennzahlen angegeben SQL-Server-Aggregats-Funktionen (Windowed Functions) zu verwenden:
- Ranking Urlaubszeit:
NTILE(3)—NTILE(3)teilt die zu beurteilende Menge der Mitarbeiter (je Hierarchie-Stufe) in drei gleich große Gruppen ein. Die Zuordnung des Mitarbeiters zu einer der drei Gruppen erfolgt entsprechend der aufsteigenden Sortierung nach Urlaubszeiten. - Ranking Urlaubszeit:
DENSE_RANK—DENSE_RANKermittelt zu jedem Mitarbeiter (je Hierarchie-Stufe) eine Position in einer Rangfolge. Liegen zu zwei Mitarbeitern z. B. die gleiche Anzahl Urlaubsstunden vor, erhalten beide Mitarbeiter die gleiche Position im Ranking. - Ranking Krankheitszeit:
NTILE(3)— analog zu Urlaubszeit. - Ranking Krankheitszeit:
DENSE_RANK— analog zu Urlaubszeit.
Diese Aufgabe ist sowohl über ein SQL-Statement als auch über ein SSIS-Paket zu lösen. In einem zweiten Teil sind die so entwickelten Dokumente dahingehend zu ändern, dass als Gruppierungskriterium nicht mehr die Urlaubs- und Krankheitszeiten, sondern das Einstellungsdatum des Mitarbeiters sowie sein Geburtsdatum zu verwenden ist.
Bei dieser Aufgabe gibt es zwei Herausforderungen:
- Ermittlung der Hierarchie der Mitarbeiter
- Ermittlung des Rankings
SQL-Statement
Transact-SQL stellt für beide Herausforderungen leicht zu verwendende Methoden vor:
Sind Daten — wie in der Tabelle [DimEmployee] — über eine Vater-Kind-Beziehung strukturiert, können diese Daten über eine CTE sehr effizient rekursiv ausgewertet werden:
1: CREATE OR ALTER PROCEDURE [dbo].[sp_insert_employee_hierarchy_ranking]
2: AS
3: BEGIN
4: SET NOCOUNT ON;
5:
6: TRUNCATE TABLE [dbo].[fct_employee_hierarchy_ranking];
7:
8: WITH CTE_Employee AS
9: (
10: -- Anker der rekursiven CTE: der CEO als Top-Level-Mitarbeiter ohne
11: -- Vorgesetzten. [Level] = 1 markiert die Wurzel der Hierarchie.
12: SELECT
13: [EmployeeKey]
14: ,[FirstName]
15: ,[LastName]
16: ,[Title]
17: ,[ParentEmployeeKey]
18: ,[VacationHours]
19: ,[SickLeaveHours]
20: ,1 AS [Level]
21: FROM
22: [AdventureWorksDW2017].[dbo].[DimEmployee]
23: WHERE
24: [ParentEmployeeKey] IS NULL
25:
26: UNION ALL
27:
28: -- Rekursionsschritt: alle Mitarbeiter, deren [ParentEmployeeKey] auf
29: -- einen bereits in der CTE enthaltenen Mitarbeiter zeigt. [Level] wird
30: -- pro Tiefe um 1 erhöht. UNION ALL ist die einzige rekursions-erlaubte
31: -- Mengenoperation zwischen Anker und rekursivem Glied.
32: SELECT
33: T01.[EmployeeKey]
34: ,T01.[FirstName]
35: ,T01.[LastName]
36: ,T01.[Title]
37: ,T01.[ParentEmployeeKey]
38: ,T01.[VacationHours]
39: ,T01.[SickLeaveHours]
40: ,T00.[Level] + 1 AS [Level]
41: FROM
42: [AdventureWorksDW2017].[dbo].[DimEmployee] AS T01
43: INNER JOIN
44: CTE_Employee AS T00
45: ON
46: T01.[ParentEmployeeKey] = T00.[EmployeeKey]
47: WHERE
48: T01.[Status] = N'Current'
49: )
50: INSERT INTO [dbo].[fct_employee_hierarchy_ranking]
51: (
52: [ParentEmployeeKey]
53: ,[EmployeeKey]
54: ,[LastName]
55: ,[FirstName]
56: ,[Title]
57: ,[Level]
58: ,[VacationHours]
59: ,[SickLeaveHours]
60: ,[VacationHours_NTILE]
61: ,[VacationHours_DENSE_RANK]
62: ,[SickLeaveHours_NTILE]
63: ,[SickLeaveHours_DENSE_RANK]
64: )
65: SELECT
66: [ParentEmployeeKey]
67: ,[EmployeeKey]
68: ,[LastName]
69: ,[FirstName]
70: ,[Title]
71: ,[Level]
72: ,[VacationHours]
73: ,[SickLeaveHours]
74: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_NTILE]
75: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [VacationHours], [EmployeeKey]) AS [VacationHours_DENSE_RANK]
76: ,NTILE(3) OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_NTILE]
77: ,DENSE_RANK() OVER (PARTITION BY [Level] ORDER BY [SickLeaveHours], [EmployeeKey]) AS [SickLeaveHours_DENSE_RANK]
78: FROM
79: CTE_Employee;
80: END;
81: GO
Dieses Statement liefert zu jedem Mitarbeiter in der Spalte [Level] die Hierarchiestufe sowie die geforderten Kennzahlen entlang der Urlaubszeiten sowie Krankheitszeiten. Insgesamt sind die 254 Mitarbeiter in 5 Hierarchiestufen organisiert.

Der Vergleich des oben gezeigten Statements mit einer modifizierten Version (in der VacationHours durch HireDate und SickLeaveHours durch BirthDate ersetzt sind) wird in Visual Studio als das erste Diff-Beispiel oben dargestellt — drei Spalten-Edits, ein Datentyp-Wechsel, der Diff zeigt die ~15 betroffenen Zeilen klar lokalisiert.
SSIS-Paket
So einfach diese Aufgabe über T-SQL zu lösen war, so schwer und vor allem zeitraubend war die Entwicklung der Lösung in SSIS, wenn man für die Lösung ausschließlich die Werkzeuge von SSIS verwenden möchte. Für die hier dargestellte Lösung wurde der folgende Ansatz gewählt:
- Je Aufgabe werden zwei Tabellen in der Datenbank benötigt.
- Der Data Flow 1000 DFT Calculate Levels ermittelt ausschließlich die Hierarchie.
- Der Data Flow 3000 DFT Calculate Ranking ermittelt ausschließlich das Ranking und speichert das Ergebnis in einer Tabelle.
- Das Ranking wird für Urlaubs-/Krankheitszeiten jeweils über zwei Skript-Tasks ermittelt.
Möglicherweise gibt es auch eine viel einfachere Lösung.
Control Flow
Der Control-Flow des SSIS-Paketes gestaltet sich mit 4 Tasks noch recht einfach.

Data Flow 1000 DFT Calculate Levels
Während die Lösung über T-SQL einen rekursiven Ansatz unterstützt, ist dieses bei SSIS (nach meinem Kenntnisstand) nicht möglich. Die Zuordnung der 5 Hierarchiestufen muss daher je Stufe entwickelt werden..

Data Flow 3000 DFT Calculate Ranking
Die eigentliche Berechnung des Rankings erfolgt in Skript-Tasks durch Vergleich zwei aufeinander folgender Datensätze.

Anpassung des Paketes
Nach Fertigstellung des Paketes wurde das Paket in Git committet (bzw. in einem On-Prem-Stack via Azure DevOps Server) und anschließend so abgeändert, dass als Ordnungskriterium für die Ermittlung des Rankings nicht mehr Urlaubs-/Krankheitszeiten sondern Einstellungs-/Geburtstage verwendet werden. Im Wesentlichen sind hier drei Feldnamen und ein Datentyp zu ändern gewesen. Trotz der größeren Anzahl der verwendeten Tasks hat sich der Umfang der Änderungen in Grenzen gehalten und war in wenigen Minuten erledigt. Das Ergebnis wurde ebenfalls committet.
Vergleich der zwei Versionen
Ein Vergleich der beiden committeten Versionen ergab die folgenden Änderungen:

Maßgeblich für die Beurteilung des Umfangs der Änderung in dem SSIS-Paket ist der rechte vertikale Scroll-Balken. Rechts neben dem Scroll-Balken sind die Fundstellen der Änderungen in dem SSIS-Paket farblich in grüner und roter Farbe hervorgehoben. Trotz des eher geringen Umfangs der Änderungen ist förmlich das gesamte SSIS-Paket auf den Kopf gestellt worden.
Während die Lösung der Aufgabe in T-SQL relativ schnell entwickelt werden kann, ist die Entwicklung des SSIS-Paketes aufwändig und sie hat mehrere Stunden Zeit gekostet. Grund hierfür waren im Wesentlichen die schlechte Lesbarkeit eines SSIS-Paketes, aber auch die (überraschende) Erkenntnis, dass es für die vermeintlich einfache Aufgabe keinen Out-Of-The-Box-Lösungsansatz in SSIS gibt. Zu Beginn habe ich mit einer einzigen Formel-Expression experimentiert, die die Hierarchie-Ebene berechnet — nach zwei oder drei Stunden habe ich die weiße Fahne geschwenkt und den hier dargestellten Ansatz gewählt, auf Kosten der Lesbarkeit und Flexibilität des SSIS-Paketes.
Nach Fertigstellung und einem Commit der Lösung waren nur noch vergleichsweise wenige Änderungen erforderlich, um das Ordnungskriterium für die Berechnung der Kennzahlen zu ändern. Die wenigen Änderungen resultieren in zahlreichen Änderungen in dem zugrunde liegenden XML-Dokument. Ein Versions-Vergleich lässt den Entwickler ratlos zurück, was sich denn nun in dem SSIS-Paket geändert hat. Zum Vergleich mit T-SQL: Hier ist zum einen der Lösungsweg direkt lesbar und Änderungen sind nachvollziehbar.
Versionskontrolle 2026
Die Kernfrage des Artikels — wie diffbar ist ein Entwicklungs-Artefakt — ist 2026 keine reine SQL-Server-/SSIS-Frage mehr. Der Microsoft-Stack ist nur eine Option neben anderen, und das Diff-Pragmatik-Argument überträgt sich Stack-übergreifend.
Microsoft-Stack heute
Visual-Studio-Datenbankprojekte gibt es heute in zwei Varianten — klassisches SSDT (.sqlproj, MSBuild-Legacy) und SDK-style (Microsoft.Build.Sql, in Preview, kompatibel zur VS-Code-mssql-Extension); beide bleiben supported. SSIS-Projekte laufen separat über die SSIS-Projects-Extension für Visual Studio 2022+ und sind weiter .dtsx-XML-basiert, das GUID-Reordering-Problem ist unverändert. Microsoft selbst hat den Versionskontroll-Standard von Team Foundation Server (TFS) auf Git verschoben — Azure DevOps Server ist der TFS-Nachfolger und unterstützt Git als modernen VCS-Backend (TFVC bleibt für Bestands-Kompatibilität optional verfügbar). Der Cloud-Wechsel zu Azure Data Factory + Synapse Pipelines bringt das gleiche Diff-Problem in JSON-Definition statt XML — das Tool wechselt, die Artefakt-Format-Frage bleibt.
Git-Welt
Außerhalb des Microsoft-Stacks ist die Welt offener und SQL-zentrierter. Drei Bausteine prägen die Versionskontroll-Praxis 2026:
- Git als Default-VCS. GitHub, GitLab, Bitbucket. SP-Diffs sind Plain-Text-Diffs, in jedem Pull-Request-Tool trivial reviewbar.
- Schema-Migrations-Tools. Liquibase und Flyway versionieren Schema-Änderungen als Plain-SQL-Migrations-Files. Jede
V001__add_employee_table.sqlist diffbar wie ein normales SQL-Skript. - sqlmesh. sqlmesh versioniert SQL-Pipelines mit explizitem State-Tracking — die
.sql-Files sind die versionierten Artefakte, der Wartbarkeits-Hebel ist derselbe wie bei einer Stored Procedure, nur stack-agnostisch (Postgres, Snowflake, BigQuery, Redshift, Databricks, ClickHouse, DuckDB, Microsoft Fabric u. a.). Seit März 2026 ist sqlmesh Linux-Foundation-Projekt (zuvor Tobiko Data, inzwischen Teil von Fivetran) und damit unter Community-Governance statt Single-Vendor.
Die Frage bleibt: was lässt sich diffen?
Stack-übergreifend dieselbe Pointe: das Artefakt-Format entscheidet, nicht das Tool. Plain-SQL (SP, Liquibase-/Flyway-Migration, sqlmesh-Model) lässt sich trivial diffen. XML/JSON mit GUID- und Position-Properties (.dtsx, ADF-Pipeline-JSON) braucht Spezial-Tools wie BIDS Helper oder Strukturbaum-Diff-Erweiterungen.
Wer ETL-Logik versionierbar halten will, packt die Substanz in SQL-Artefakte. Wer SSIS-Pakete trotzdem versionieren muss, ergänzt das mit:
- BI Developer Extensions (ehemals BIDS Helper) oder das SSIS Compare and Merge Tool aus dem Visual Studio Marketplace (Strukturbaum-Diff statt XML-Diff — beides Community-Tools; ein offizielles SSDT-Feature mit GUID-Filter gibt es nicht).
- Screenshot-Diff der
Control Flow– undData Flow-Designer als visueller Pragmatik-Ansatz. - Begleitende SQL-Skripte in Stored Procedures auslagern, sodass das
.dtsxnur Orchestrierung enthält und der inhaltliche Diff im SQL-Skript stattfindet. Das ist die strategische Antwort — und SSIS vs. SQL: Lesbarkeit und Wartbarkeit — wie viel SQL gehört in ein SSIS-Paket? macht denselben Punkt aus der Wartbarkeits-Perspektive.
Take-Away
- SP-Diffs sind lesbar,
.dtsx-Diffs sind es nicht. Das ist eine strategische Architektur-Entscheidung, keine Tool-Frage — und sie überträgt sich Stack-übergreifend auf jedes XML-/JSON-basierte ETL-Format. - Trivialer Edit ≠ trivialer Diff. Eine Skript-Task-Umbenennung erzeugt acht XML-Bereich-Markierungen, und der Diff lokalisiert den eigentlichen Edit nicht korrekt. Wer Audit-Trail will, muss das Artefakt-Format diff-tauglich wählen.
- Versionierbarkeit ist Artefakt-Format-Frage. Plain-SQL gewinnt: Stored Procedure, Liquibase-/Flyway-Migration, sqlmesh-Model. XML/JSON-Artefakte sind diffbar nur mit Spezial-Tools.
- Strategische Antwort: ETL-Substanz in SQL-Artefakte auslagern,
.dtsx-Pakete (oder ADF-Pipelines) als reine Orchestrierung halten. Damit lebt der Audit-Trail im SQL-Diff.
FAQ
.dtsx-Pakete überhaupt sinnvoll in Git versionieren? Ja — aber der Diff-Wert ist begrenzt. Du kannst .dtsx-Dateien problemlos committen und mergen, aber bei jedem Edit erzeugt SSIS XML-Reorderings durch GUIDs und Position-Properties. Praktische Antwort: committen plus zusätzlich ein lesbarer Begleit-Diff via BIDS Helper, Screenshot-Diff oder SQL-Auslagerung.
.dtsx-Diff? Es gibt mehrere Annäherungen: (1) BI Developer Extensions (ehemals BIDS Helper) für Visual Studio mit Smart-Diff (Strukturbaum-Diff statt XML-Diff) — Marketplace-Builds offiziell für VS 2017/2019, kein vollständiger VS-2022-Build verfügbar. (2) SSIS Compare and Merge Tool aus dem Visual Studio Marketplace — Community-Tool, das den GUID-Rausch-Filter abdeckt und auch in VS 2022 läuft; SSDT selbst liefert keinen .dtsx-spezifischen Diff. (3) Screenshot-Diff der Control Flow– und Data Flow-Designer ist pragmatisch — kein versionierter Diff, aber visuell direkt erfassbar. Jedes dieser drei Tools ist besser als der naive XML-Diff.
Praktisch: SQL-Artefakte (SPs, Views, Functions) als Visual-Studio-Datenbankprojekt mit *.sql-Files, SSIS-Pakete als separates Visual-Studio-Integration-Services-Projekt mit *.dtsx-Files. Beide Projekte landen im selben Git-Repo, aber die Pull-Request-Reviews unterscheiden Datentypen: SQL-Diffs sind Plain-Text reviewbar, SSIS-Diffs brauchen den Strukturbaum-Diff oder Screenshot-Komplement. Best Practice: viel SQL in SPs auslagern, dann reduziert sich das .dtsx-Diff-Problem auf reine Orchestrierungs-Edits.
Drei Zeilen in einer GitHub-/GitLab-/Azure-DevOps-PR-Ansicht — die geänderten Zeilen sind hellgrün markiert, gelöschte rot. Der Reviewer sieht in 30 Sekunden, dass [VacationHours] durch [HireDate] ersetzt wurde und der Datentyp von float auf date gewechselt hat. Genau dieses Pattern macht den Audit-Trail einer ETL-Pipeline überhaupt erst praktikabel.
Verwandte Artikel
SSIS-vs.-SQL-Cluster:
- SSIS vs. SQL — die Cluster-Wurzel mit der grundsätzlichen Tool-Diskussion.
- SSIS vs. SQL: Identitätswechsel — Schwester-Artikel zum
EXECUTE AS-Pattern. - SSIS vs. SQL: Lesbarkeit und Wartbarkeit — die Wartbarkeits-Perspektive zum gleichen DimEmployee-Beispiel; baut auf der Diff-Argumentation dieses Artikels auf.
ETL-Kontext:
- Design Pattern // Architektur eines ETL-Prozesses — Big-Picture für die Strecken-Architektur.
- Datenqualität in einem ETL-Prozess — Datenqualitäts-Bausteine, die in jeder versionierten ETL-Pipeline mitlaufen müssen.
- Design Pattern // Protokollierung eines ETL-Prozesses mit SQL — Logging-Pattern, das den Audit-Trail-Vorteil von SQL noch verstärkt.