An SSIS package fails, you open the execution log to find the cause — and face a tree in which the tasks don’t appear in the order they ran, but alphabetically by name. For complex packages that log is simply unreadable. The good news: a well-thought-out naming convention solves the problem completely — without any code.
The essentials up front:
- The problem: SSIS logs tasks alphabetically by task name per container, not in execution order — in the Progress tab as well as in the Integration Services Catalog reports.
- Numbering as a prefix brings the tasks in the log into their real execution order.
- A type prefix (
DFT,SQL,SCR, …) makes the task type recognizable in the purely textual log. - A meaningful name plus the overall syntax
XXXX [YYYY] ZZZ Namemakes every task name unique and self-explanatory. - Beyond today’s SSIS: the convention still applies via the VS 2022/2026 extension, and its principle carries over to modern ETL tools (Azure Data Factory, Fabric, dbt, Airflow).
Prerequisite: an SSIS project in Visual Studio (with the SQL Server Integration Services Projects extension). The screenshots are from Visual Studio 2017; the convention applies regardless of version.
Contents
- Why SSIS Tasks Need a Naming Convention
- Numbering of tasks according to their execution order
- Use a Prefix for Each Task Type
- Task names
- Naming Convention
- SSIS Today: Tooling Update and Context
- FAQ
Why SSIS Tasks Need a Naming Convention
The definition of programming guidelines and naming conventions only makes sense if the advantage outweighs the effort. One important prerequisite is identifying the benefits. Readability and maintainability of code are generally the focus when talking about naming conventions. In the case of SQL Server Integration Services (SSIS), however, another aspect comes into play: the logging of a package’s execution in the Execution Results / Progress tab in Visual Studio. The execution is logged in a tree view. For complex packages with sub packages, For Each Loop Containers, Sequence Containers, etc., the tree quickly becomes long and deep. It is hard to follow the execution order of tasks in the tree and, in case of an error, to identify the cause quickly. Who hasn’t struggled with this supposedly simple task?!
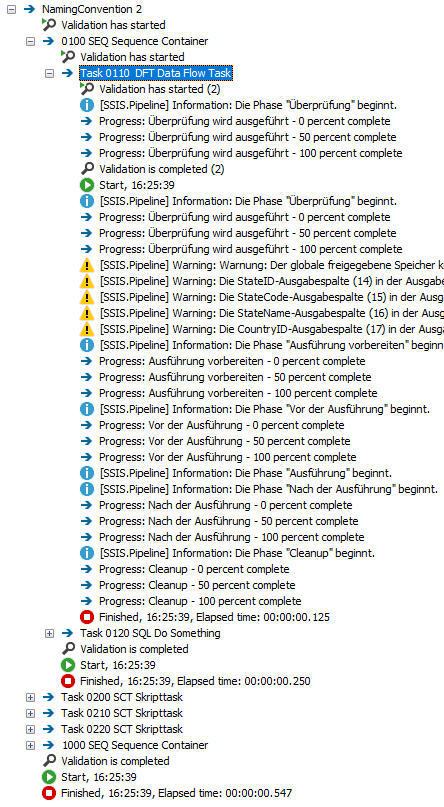
Let’s have a look behind the scene. Visual Studio orders all tasks in the Execution Result tab by the task name and not the execution order of the tasks. The following screenshot shows the execution of a rather simple package in Visual Studio 2017:

Annotations:
- There are two Sequence Containers. The names of the containers are identical except the suffix. The container with the suffix 2 is executed prior to the container with the suffix 1.
- Both Sequence Containers contain identical Control Flow Tasks. In each container the Control Flow Task with the prefix 2 is executed prior to the Control Flow Task with the prefix 1.
- In between both Sequence Containers you find three Script Tasks. The task names are prefixed with the letters A, B and C in opposition to the execution order which is C, B and A.
Both Control Flow Tasks with type of Data Flow Task are identical. The alphabetically ordered task names do not reflect the actual execution order which is OLE-DB Source prior to Count.
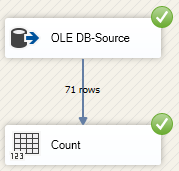
Have a look at the Execution Results tab. The tasks are not ordered by the order of their execution but by their names:
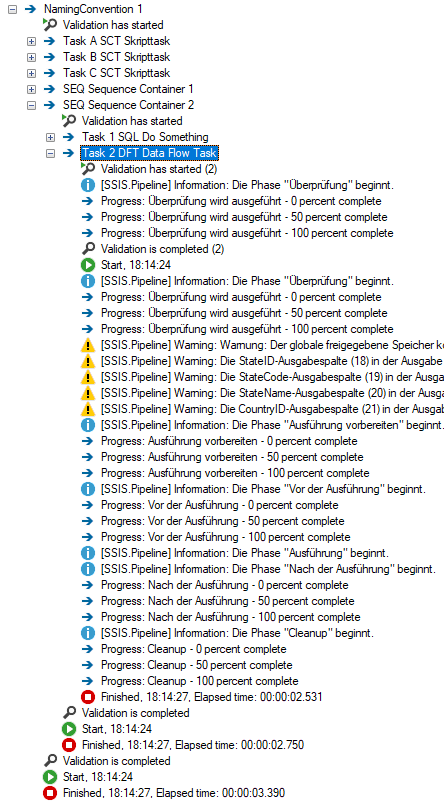
Any execution result of complex transformations in SSIS must appear to be not legible. Frankly, I would like to get to know Microsoft’s thoughts on that.
The above shown screenshots are taken from Visual Studio. But is the situation different when deploying and executing an SSIS Package in SQL Servers’ Integration Services Catalogs? Reports on the package executions within the Integration Services Catalogs can be opened by
right-click on project/package > Reports | Standard Reports | All Executions
In fact, the overview site of any execution orders the log entries by the task names, too.
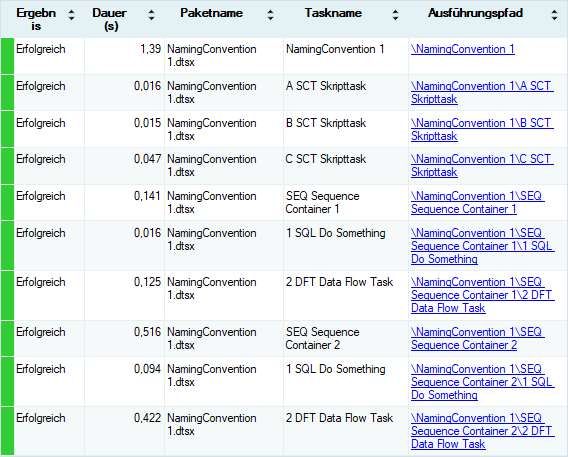
This leads me to the conclusion that task names should be chosen in a way that the displayed order of executed tasks corresponds to the actual execution order of the tasks. Three commonly followed naming conventions for SSIS tasks address this:
- Use a meaningful numbering of tasks according to their actual execution order
- Use a prefix for each task type
- Use meaningful task names
Numbering of tasks according to their execution order
When thinking of a meaningful numbering of task names we should distinguish Control Flow Tasks from Data Flow Tasks.
Control Flow Tasks
Using Numbers as a prefix ensures that tasks will be logged in the right order according to the order of their execution.
The numbering should support a four-digit range (numbers up to 9999). Smaller numbers should be entered with leading zeros. Don’t use consecutive numbers. Leaving gaps between two numbers allows for changing the execution order of tasks by minimizing the effort for the modification of task names through adjusting the numbering.
Of course, numbering tasks is time consuming, but the advantage outweighs the effort. The experiences made in multi developer projects prove to be beneficial when dealing with errors:
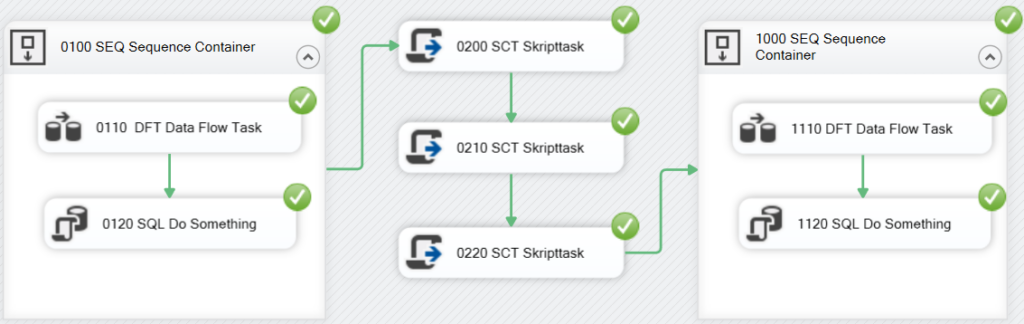
The following execution result shows the execution plan of the above package. All tasks are ordered according to their task name. With that the execution log appears to be much more legible than the first version in this article:
Data Flow Tasks
The execution of Data Flow Tasks is normally not logged in the execution log, but it is recommended to apply a numbering convention to Data Flow Tasks, too. In fact, the convention should be extended as stated after the next screenshot.
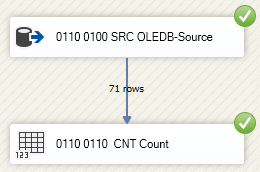
The first executed Control Flow Task was prefixed with the number 0110. All Data Flow tasks should be prefixed with the same number followed by a numbering for all Data Flow Tasks. This allows an unambiguous identification of any Data Flow Task in a package. When using this naming convention all Data Flow Tasks are prefixed with two numbers:
- Control Flow number
- Data Flow number
But in which situation proves this convention to be beneficial. In case of exceptions fired by a Data Flow Task SSIS logs the task name of the Data Flow Tasks that fired the exception. Unique names help to identify the task that has fired an exception:

Use a Prefix for Each Task Type
Each task type has its own pictogram. However, the representation of task types is limited to the size of icons which is 16×16 pixel. Moreover, a pictogram is just a visual representation. The identification of task types in an execution log requires prefixes that indicate the type of a task.
To increase the readability, it is therefore common sense that task names should be prefixed with an abbreviation depending on the task type:
- DFT for Data Flow Task
- SCT for Script Task
- SQL for SQL Execute Task
- …
The internet provides a few lists with suggestions for such abbreviations/prefixes. The following two tables contain the abbreviations/prefixes used by me.
Prefixes for Control Flow Tasks
| Task | Prefix |
|---|---|
| Back Up Database Task | BACKUP |
| CDC Control Task | CDC |
| Check Database Integrity Task | CHECKDB |
| Data Profiling Task | DPT |
| Execute SQL Server Agent Job Task | AGENT |
| Execute T-SQL Statement Task | TSQL |
| History Cleanup Task | HISTCT |
| Maintenance Cleanup Task | MAINCT |
| Notify Operator Task | NOT |
| Rebuild Index Task | REBIT |
| Reorganize Index Task | REOIT |
| Shrink Database Task | SHRINKDB |
| Update Statistics Task | STAT |
| For Loop Container | FLC |
| Foreach Loop Container | FELC |
| Sequence Container | SEQC |
| ActiveX Script | AXS |
| Analysis Services Execute DDL Task | ASE |
| Analysis Services Processing Task | ASP |
| Bulk Insert Task | BLK |
| Data Flow Task | DFT |
| Data Mining Query Task | DMQ |
| Execute Package Task | EPT |
| Execute Process Task | EPR |
| Execute SQL Task | SQL |
| Expression Task | EXPR |
| File System Task | FSYS |
| FTP Task | FTP |
| Message Queue Task | MSMQ |
| Script Task | SCR |
| Send Mail Task | SMT |
| Transfer Database Task | TDB |
| Transfer Error Messages Task | TEM |
| Transfer Jobs Task | TJT |
| Transfer Logins Task | TLT |
| Transfer Master Stored Procedures Task | TSP |
| Transfer SQL Server Objects Task | TSO |
| Web Service Task | WST |
| WMI Data Reader Task | WMID |
| WMI Event Watcher Task | WMIE |
| XML Task | XML |
Prefixes for Data Flow Tasks
| Task | Prefix | Type | Supplier |
|---|---|---|---|
| ADO NET Source | ADO_SRC | Source | |
| Azure Blob Source | AB_SRC | Source | |
| CDC Source | CDC_SRC | Source | |
| DataReader Source | DR_SRC | Source | |
| Excel Source | EX_SRC | Source | |
| Flat File Source | FF_SRC | Source | |
| HDFS File Source | HDFS_SRC | Source | |
| OData Source | ODATA_SRC | Source | |
| ODBC Source | ODBC_SRC | Source | |
| OLE DB Source | OLE_SRC | Source | |
| Raw File Source | RF_SRC | Source | |
| SharePoint List Source | SPL_SRC | Source | |
| XML Source | XML_SRC | Source | |
| Aggregate | AGG | Transformation | |
| Audit | AUD | Transformation | |
| Balanced Data Distributor | BDD | Transformation | |
| Cache Transform | CCH | Transformation | |
| CDC Splitter | CDCS | Transformation | |
| Character Map | CHM | Transformation | |
| Conditional Split | CSPL | Transformation | |
| Copy Column | CPYC | Transformation | |
| Data Conversion | DCNV | Transformation | |
| Data Mining Query | DMQ | Transformation | |
| Derived Column | DER | Transformation | |
| DQS Cleansing | DQSC | Transformation | |
| Export Column | EXPC | Transformation | |
| Fuzzy Grouping | FZG | Transformation | |
| Fuzzy Lookup | FZL | Transformation | |
| Import Column | IMPC | Transformation | |
| Lookup | LKP | Transformation | |
| Merge | MRG | Transformation | |
| Merge Join | MRGJ | Transformation | |
| Multicast | MLT | Transformation | |
| OLE DB Command | CMD | Transformation | |
| Percentage Sampling | PSMP | Transformation | |
| Pivot | PVT | Transformation | |
| Row Count | CNT | Transformation | |
| Row Sampling | RSMP | Transformation | |
| Script Component | SCR | Transformation | |
| Slowly Changing Dimension | SCD | Transformation | |
| Sort | SRT | Transformation | |
| Term Extraction | TEX | Transformation | |
| Term Lookup | TEL | Transformation | |
| Union All | ALL | Transformation | |
| Unpivot | UPVT | Transformation | |
| ADO NET Destination | ADO_DST | Destination | |
| Azure Blob Destination | AB_DST | Destination | |
| Data Mining Model Training | DMMT_DST | Destination | |
| Data Streaming Destination | DS_DST | Destination | |
| DataReaderDest | DR_DST | Destination | |
| Dimension Processing | DP_DST | Destination | |
| Excel Destination | EX_DST | Destination | |
| Flat File Destination | FF_DST | Destination | |
| HDFS File Destination | HDFS_DST | Destination | |
| ODBC Destination | ODBC_DST | Destination | |
| OLE DB Destination | OLE_DST | Destination | |
| Partition Processing | PP_DST | Destination | |
| Raw File Destination | RF_DST | Destination | |
| Recordset Destination | RS_DST | Destination | |
| SharePoint List Destination | SPL_DST | Destination | |
| SQL Server Compact Destination | SSC_DST | Destination | |
| SQL Server Destination | SS_DST | Destination | |
| Microsoft Dynamics 365 CE/CRM Source | CRM_SRC | Source | KingswaySoft Software |
| Microsoft Dynamics 365 CE/CRM Destination | CRM_DST | Destination | KingswaySoft Software |
| Oracle Eloqua Source | ELO_SRC | Source | KingswaySoft Software |
| Oracle Eloqua Destination | ELO_DST | Destination | KingswaySoft Software |
Task names
Finally, task names should briefly describe what the task does. For example, Import Customer, Check Data Types, etc.
Naming Convention
All tasks (Control Flow Tasks and Data Flow Tasks) within a SSIS package should have a unique name. The following naming convention provides a rule for specifying a unique name:
XXXX [YYYY] ZZZ Name
with
XXXX
- Numbering of Control Flow Tasks.
- The numbering of Control Flow Tasks should support a four-digit number range (up to 9999).
- Smaller numbers should be prefixed with leading zeros.
- Don’t use consecutive numbers. Leaving gaps between two numbers allows for changing the execution order of tasks by minimizing the effort for the modification of task names through adjusting the numbering.
YYYY
- Numbering of Data Flow Tasks.
- The numbering of Data Flow Tasks contains as a prefix the number of the containing Control Flow Task with type of Data Flow (XXXX).
- The numbering of Data Flow Tasks should support a four-digit number range (up to 9999).
- Smaller numbers should be prefixed with leading zeros.
- Don’t use consecutive numbers. Leaving gaps between two numbers allows for changing the execution order of tasks by minimizing the effort for the modification of task names through adjusting the numbering.
ZZZ
- Prefix that allows identifying the type of a Control Flow or Data Flow Task.
- Refer to the above given prefixes.
Name
- Task names should briefly describe what the task does.
SSIS Today: Tooling Update and Context
The screenshots in this article are from Visual Studio 2017 — the convention itself has been valid ever since. What has changed is the tooling: SSIS packages are built today with the separately installed SQL Server Integration Services Projects 2022+ extension, which supports Visual Studio 2022 and 2026 and targets SQL Server versions from 2017 through 2025. The tabs (Progress / Execution Results) and the Integration Services Catalog reports have stayed the same.
Version note: The behaviour described here — tasks logged alphabetically by name rather than in execution order — is long-standing field experience (screenshots: Visual Studio 2017). Microsoft’s documentation describes the Progress tab generically as “in execution order”. If in doubt, check quickly in your SSIS version whether the sorting still applies — it doesn’t change the value of the convention either way.
Why “either way”? The three building blocks work independently of the exact sort order: a numbering makes the log scannable, a type prefix makes the task type recognizable in plain text, and a unique name allows unambiguous attribution in case of an error — no matter how the entries are arranged.
Where ETL Is Heading
SSIS remains the established on-premises ETL engine and is still maintained. For new projects, however, the focus is shifting: in the Microsoft world, Azure Data Factory and Microsoft Fabric take over cloud orchestration; in the open-source and Postgres ecosystem, dbt (transformation) and Apache Airflow (orchestration) have become established. The core idea of this article carries over directly: there, too, consistent naming of steps and models decides whether a run log stays readable.
FAQ
SSIS sorts the tasks in the execution log alphabetically by task name per container — in the Progress / Execution Results tab in Visual Studio as well as in the Integration Services Catalog reports. The actual execution order is irrelevant to the display. That’s exactly why a numbering prefix helps: it brings the alphabetical sort into line with the execution order.
Each Data Flow Task gets two four-digit numbers as a prefix: first the number of the parent Control Flow Task of type Data Flow, then its own number within the data flow. That keeps every task uniquely identifiable even in the error log. Both number ranges should leave gaps so the order can later be changed without renaming all tasks.
There is no official Microsoft standard — the two tables above list the common prefixes used here (DFT for Data Flow Task, SQL for Execute SQL Task, SEQC for Sequence Container, and so on). What matters is less the exact abbreviation than team-wide consistency: agree on the list once and stick to it.
Yes. The naming convention is one building block of maintainable SSIS solutions, alongside logging an ETL process, the source code management of SSIS packages, and the fundamental trade-off of SSIS vs. T-SQL and how much SQL belongs in an SSIS package.