A single date string that cannot be parsed, and the entire ETL run aborts. The design pattern for ETL process architecture presented here prevents exactly that: bad data is isolated, not passed along.
TL;DR — what this article covers:
- Work packages and schema layering E0 – L2 — how to decompose the ETL process into distinct, self-contained packages, each with its own database schema.
- Technical vs. structural transformation — why separating type conversion and foreign-key resolution into two passes is safer and easier to debug than doing both in one.
- Data quality at the schema boundaries — erroneous records are caught at the transitions; the main stream keeps flowing cleanly.
- Historization as an optional layer — SCD 1 / SCD 2 pay off mostly when delta loads are involved.
Prerequisite. Basic familiarity with ETL processes. This is a conceptual article — not a step-by-step tutorial. Root of the article series: Data quality in an ETL process; the present article covers the architecture part.
Contents
Tasks of the ETL Process
An ETL process consists of the three general steps E = Extract, T = Transform and L = Load. What exactly has to happen within each of these top-level steps, however, is a matter of definition.
Extraction
In this step, data is extracted from various data sources. Sources can be databases, files, or APIs. The data to be extracted may be structured or unstructured and may come in different formats. This article series deals exclusively with structured data. Structured data sources include relational databases, but also CSV documents as well as XML and JSON documents — as long as their data elements follow a logical structure. Unstructured data such as text from social networks is out of scope here.
This generic definition leaves open what extraction concretely means. The following sections describe a concrete shape for the extraction process:
- Materialization of the extracted data
- Extended extraction tasks
- No type conversion of the data
Materialization of Extracted Data
The design pattern presented here stores all extracted data in a database. The data must be stored in such a way that, in this step, there is no technical reason for the data not to fit into the database. The only acceptable cause for aborting extraction is an infrastructure issue (storage, network, etc.). I refer to this writing-to-database step as the materialization of the data.
Extraction and the materialization of extracted data give three main benefits:
- The source system is read only once and as briefly as possible.
- All extracted data is available in a database for subsequent processing.
- After-the-fact error analysis on concrete records becomes possible.
Reading from the source system can put it under enough load that its performance and response times suffer. Extracting first minimizes the duration of that access.
Once all extracted data sits in a database, downstream steps can work on it using SQL. No additional ETL tool is required just to integrate heterogeneous source systems. This lowers technical hurdles and, in practice, makes the downstream processes substantially more performant — both in execution and in development.
Extended Extraction Tasks
For text files in XML and JSON format (and, depending on the case, CSV), materialization works a bit differently. XML and JSON documents are stored in the database before their contained attributes are extracted. As an extended extraction task, the attributes are then extracted from the stored documents using powerful T-SQL functions such as OPENXML or OPENJSON and written to the database.
No Type Conversion of the Data
Text-file deliveries are particularly problematic. The data they contain is not type-safe by any means. A date delivered as text may or may not be convertible into a date value. There has to be an agreement between the source-data-producing process and the ETL process about, for example, which date format is used (yyyy/dd/MM, dd.MM.yyyy, etc.). Converting values during extraction is a source of errors and risks aborting the entire ETL run. Converting data into the target data types is therefore not permitted during extraction.
Transformation
A common definition of the transformation step goes something like: “Transformation converts the extracted data into the desired format.” Another definition lumps all the tasks under the term data integration. Both phrasings are vague and offer no concrete guidance.
Starting from the extracted data, the design pattern presented here defines two mandatory tasks and one optional task:
- Type conversion of the extracted data
- Data quality check
- Optional: historization
When data arrives as text files, the extracted attributes must first be converted into the target data types. This also applies when data is extracted from databases whose data types diverge from those in the target system. We focus here on text files as the data source. As described above, values extracted from text files are first stored as text. The target system, however, expects strongly typed data. A date, for example, will routinely have to be converted into a value of type date.
The data quality check is, on top of that, a critically important task that fundamentally shapes the outcome of an ETL run. It starts with the question whether a delivered value can be converted into the data type of the corresponding target field. Where required, deliveries must also be checked for duplicates. There are many other useful and necessary checks and tasks that belong under the umbrella of data quality.
In the historization step, source data identified as changed (new, modified, or deleted records) is rolled forward in separate tables, so it is always reproducible when a record was inserted, modified, or deleted. This step is optional. A colleague once called the historized data the brain of the ETL process: the data of the downstream target system can be reconstructed from the historized data at any point. Of course, historization comes with additional maintenance tasks such as backups.
The term data integration is, in fact, closer to what we will call structural transformation. There, data from various sources is filtered, merged, and aggregated. Although that is also a transformation task, the design pattern presented here does not perform it during T of the ETL process — it happens during L. At this point, it pays to draw a sharp terminological line between the transformation tasks described in this section and structural transformation. The transformation tasks described here, performed during T, are referred to as technical transformation. The transformation tasks performed during L are referred to as structural transformation.
The boundaries between the three top-level ETL steps are fluid and, in the end, a matter of definition.
Typing of Extracted Data
If the data source is a database such as SQL Server or Oracle, the data will typically already be strongly typed. Even so, type conversion may still be necessary to match the data types of the target system.
Example. Consider the length of text fields or the storage of a date without a time zone. Application developers do not always pay close attention to input length limits. As a result, an address field in a source system might be able to hold entire novels. Users who notice such a gap will — empirically — happily use it to dump information that simply does not belong there. If the source system does not support storage of a date with time zone, the time zone of the source system must be determined and taken into account when converting to the target data type date with time zone.
When processing attributes extracted from a text file, typing the extracted values into the target data types is always required.
Example. During extraction, attributes are stored as values of type text. A text that looks like a date to us is not necessarily convertible into a date. For instance, 30-02-2023 is not a valid date. Another example: 03-05-2023 cannot be interpreted as a date without additional context about the data source. Read in American style (mm-dd-yyyy), it becomes 05-Mar-2023; read in the typical German style (dd-mm-yyyy), it becomes 03-May-2023. Correct interpretation requires knowledge of the date format — that is, the format string. Similar challenges arise for numeric values where decimal and thousands separators must be agreed on.
Data Quality Check
The data quality check inspects the extracted and converted data for completeness and correctness. These checks cover a wide field. Examples are:
- Type conversion check
- Duplicate identification
- Spelling and orthography check on text values
- Foreign key check
- Mandatory field missing value check
- Business logic validation
The article Data quality in an ETL process introduces the term technical data quality. The check on technical data quality operates on the typed data. For data quality checks on typed data, simple logical conditions can be set up, identifying errors on a value or per-record basis. A logical condition is technically expressed as a WHERE clause in the ETL process and applied to the typed data. If a WHERE clause returns records, those records contain an error in the inspected field.
Type Conversion Check
Whether the type conversion succeeds or fails has direct impact on all downstream tasks. If an input value cannot be converted into the target data type, the offending record may have to be excluded from further processing. The design pattern presented here checks for every delivered source record whether its input values can be converted into the respective target data types.
Duplicate Identification
Duplicate identification can be arbitrarily complex. In this article series, I limit myself to a combination of fields that, per the delivery contract, must follow a defined cardinality or must be unique (cardinality = 1).
Spelling and Orthography Check on Text Values
Phone numbers, for instance, have many possible notations. The German DIN 5008 standard prescribes that the area code be written without parentheses and separated from the rest of the number by a single space. Notation checks on a value can be performed as part of the technical transformation.
Foreign Key Check
If the delivered data contains a foreign key relationship, only the structural validity of a delivered foreign key value is checked here — that is, format, presence where required, and data type. The actual foreign key resolution against the target system (mapping source-system code → target surrogate key) only happens later, as part of the structural transformation. The reason for the split: resolution needs context from the target system (such as a Countries table), whereas format and presence checks can be answered from the record alone.
Mandatory Field Missing Value Check
If an attribute is a mandatory field in the target system, the typed data must be inspected to ensure that a corresponding value was delivered.
Business Logic Validation
Checking business logic is itself a wide field that can become arbitrarily complex. Even checking simple business logic can substantially improve data quality. A simple example might be a customer’s date of birth — which obviously must not lie in the future.
Loading
In the final step of the ETL process, the typed data is structurally transformed to match the data structures of the target system, optionally re-checked for data errors, filtered, aggregated, historized, and finally loaded into the target system. The tasks involved are:
- Structural transformation
- Data quality check
- Filtering
- Aggregation
- Optional: historization
- Loading the data into the target system
The previously technically transformed data can be loaded into different target systems. The target could be a CRM system or a data warehouse. The structural transformation task is specific to the chosen target system. That is why the structural transformation happens during L of the ETL process. Again: the boundaries between the top-level ETL steps are fluid, and it is a matter of definition which tasks fall into which step.
Structural Transformation
The structural transformation operates exclusively on the typed, quality-checked, and possibly historized data that was found to be error-free. Technically, the structural transformation corresponds to a SELECT statement joining historized tables and shaping the output to match the target system’s data structures. Among other things, this step resolves foreign keys and lookup values:
- Foreign key resolution
- Lookup value resolution
The output of the structural transformation is — as with extraction and the technical transformation — materialized in the database, so this data, too, is available for analysis and error diagnosis. The data structures of the structurally transformed data largely correspond to the structures in the target system. In particular, the column names and data types of the output are chosen to match those expected by the target.
Foreign Key Resolution
If foreign keys cannot be determined from the extracted data alone, they must be looked up against the target system’s data.
Example. Target systems often store countries in a separate table. The country United States is then identified both by its country name and — typically — by a technical key (for example, a GUID). When structurally transforming a customer whose source data identifies the country as the text United States, this text must be translated to the primary key of United States in the target system and stored as a foreign key with the customer record.
Foreign key resolution requires either direct read access to the Countries table in the target system or — if direct access is not available — that table must be read in advance and made available in the staging database. At that point, reading the Countries table is itself an extraction task.
Lookup Value Resolution
Source and target systems often use different codings for the value of a dropdown field. A dropdown field, for example, could be a list field for selecting a customer’s salutation.
In the database, what is shown and selected in the application is rarely stored verbatim. A salutation of Mr. might be stored as the value 1 and Ms. as 2. The codings used in source and target systems typically differ.
These coded attributes are often not stored in separate tables. Translating the source-system code into the target-system code therefore requires explicit knowledge of the translation rules. Following terminology used in Microsoft CRM Dynamics, this translation is called lookup value resolution. To resolve lookup values, the codes used by source and target systems must be determined and stored in a mapping table that is consulted during the structural transformation.
Data Quality Check
Experience from real projects shows that foreign key resolution and lookup value resolution are major sources of errors — typically rooted in incomplete or incorrect mappings of source-system codes to target-system codes.
Filtering
Unless the target system is being initially populated with data, only records with specific properties should be loaded into the target. Filtering for the records actually destined for loading should — where possible — already happen during the technical transformation. If that is not feasible there, filtering happens during the structural transformation.
Aggregation
Data may need to be aggregated before loading into the target system.
If end-to-end traceability of every processing step in the ETL pipeline is required, aggregation should be considered as a separate processing step downstream of the structural transformation. Aggregated data would then be stored in separate tables of the staging database.
Historization
As in the technical transformation, the structurally transformed and checked data can be rolled forward in separate tables. New records are inserted, changed records are updated, and deleted records are flagged as deleted.
Loading Data Into the Target System
The final loading of the changed data into the target system therefore operates on quality-assured, structurally transformed, and historized data. Only error-free records — those for which foreign keys and lookup values were successfully resolved — are loaded.
Technologically, this article focuses on loading change data into a target database. The target database is updated via SQL statements, that is, INSERTs, UPDATEs, and where applicable DELETEs. Other target systems — such as Microsoft Dynamics 365 — require the use of a proprietary API, both for writing data into and reading data from the target. In that case, an ETL tool such as SQL Server Integration Services is needed.
Architecture of the ETL Process
The architecture of the ETL process presented here is generic and can be used regardless of the kind of source data or target system, in data migration and data integration projects alike. It also fits the data-loading workflow of a data warehouse. The ETL process is decomposed into small, self-contained work packages. The tasks performed within a work package are sharply defined. During processing, data quality is checked at each step. After a work package finishes, only error-free data is handed over to the next package. At the end of the pipeline, quality-assured data sits in data structures similar to those of the target system and can be loaded there without further transformation.
Work Packages of the ETL Process
The following diagram illustrates the work packages of the ETL process presented here:

The top lane of the diagram shows the top-level steps from the ETL acronym: Extract, Transform, and Load. The bottom lane names the concrete work packages of the ETL process and maps each to one of the top-level steps. Each work package is paired with a database schema. The middle lane labels the database schemas used per work package (E0–L2). Data is handed from work package to work package, that is, from schema to schema, as processing progresses. The ETL process consists of the following work packages:
- Data extraction
- Technical transformation
- Historization of the technically transformed data
- Structural transformation
- Historization of the structurally transformed data
- Loading the data into the target system
The Technical Transformation and Structural Transformation work packages check the data quality of the transformed data and hand over only error-free data to the next package. In the diagram, these checks are indicated by the dark arrow heads. The sections below summarize the steps within each work package and provide an overview of the technology used to carry them out.
Extraction
The goal of extraction is to first store all data to be processed in the staging database. Within extraction, it matters whether the source data comes from a database or from documents with table-like structures (such as EXCEL or CSV) — or from documents with complex logical structures (such as XML or JSON).
Extraction From a Database

When reading from a database or from table-like structures, the attributes / columns are first materialized into tables of schema E1. The structures of the tables in schema E1 closely match the structures in the source system. When extracting from a database, the data is stored using the data types from the source system. If the source-system data types are not supported by SQL Server, the data is stored in schema E1 as nvarchar.
Extraction From Documents With Table-Like Structures

Data from documents with table-like structures — such as EXCEL and CSV — cannot be delivered in a type-safe way. These documents are often hand-authored and hand-maintained, and the ETL process cannot assume that a column contains, say, a valid date. To make sure that all values from these documents can be materialized in the staging database in tables of schema E1, all data is first stored as nvarchar. Use generous maximum text lengths to ensure that data can actually be materialized there.
Extraction From Documents With Complex Logical Structures

When XML or JSON documents are to be processed, the documents themselves are first stored in tables of schema E0. Extraction of the attributes then happens into tables of schema E1. The attribute extraction operates on the documents stored in schema E0 in the first step.
Attributes from text files are stored in schema E1 as nvarchar. Use generous maximum text lengths to ensure that the data fits.
Technology
Extraction of data from a database or from table-like structures can be done with Microsoft’s SQL Server Integration Services (SSIS) or any other ETL tool. To extract XML or JSON documents, SSIS first loads them into tables of schema E0. The attribute extraction from the documents uses the powerful T-SQL functions OPENXML or OPENJSON.
Summary
This extraction approach has several advantages. Using an ETL tool such as SSIS — which supports a high degree of parallelism in data processing — materialization into schemas E0 and E1 can be done with high throughput. Upstream systems are minimally impacted, and the data is available for further processing — including attribute extraction from XML and JSON documents via OPENXML or OPENJSON — in the staging database. The materialized data also enables root-cause analysis when errors arise.
Technical Transformation
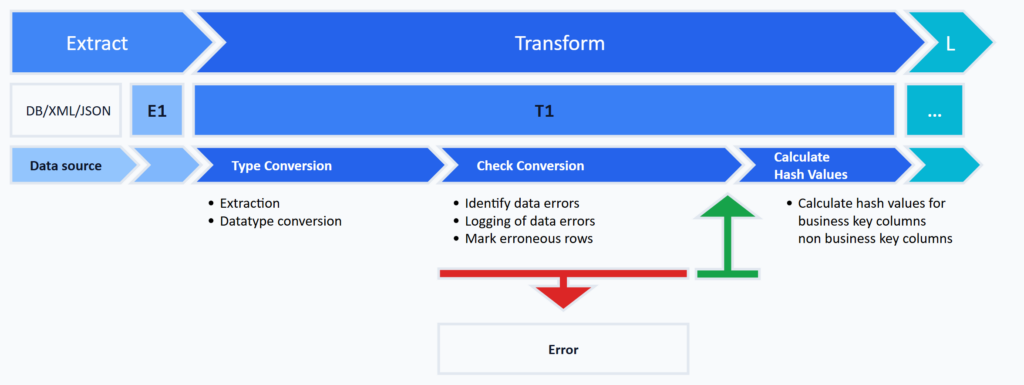
Within the top-level transformation step, this design pattern performs the technical transformation as described above. It consists of the following sub-steps:
- Type conversion
- Technical data quality check
- Data error logging
- Flagging of erroneous records
- Hash value computation
Type Conversion
The output of the technical transformation is typed data that matches the target system’s expectations. Typing can be driven by metadata via generic user-defined stored procedures and materializes the data into tables of schema T1.
Per attribute from schema E1, two columns are provided in schema T1. The first column holds the extracted value in the data type used in schema E1. The second column holds the typed value in the target data type — if the value can be converted. If the value cannot be converted, the second column stores NULL.
Technical Data Quality Check
After typing, the result is checked by comparing column pairs for type-conversion problems. Because the type conversion is purely technical, this check is also called technical data quality check. The error check can already be extended here to cover simple business logic.
Data Error Logging
Detected data errors are logged in a readable, queryable form in an error table.
Flagging of Erroneous Records
If a record contains at least one error, it is flagged as erroneous so it can be excluded from further processing. The flag lives in a column that stores the count of detected errors. Error-free records carry NULL in this column.
Hash Value Computation
The last sub-step of the technical transformation is computing and storing two hash values per record. The first hash represents the business-key columns of the record; the second hash represents all remaining columns. Through these two hashes, the next work package — Historization of Technically Transformed Data — can identify change records. Hash values are computed only for error-free records.
Technology
Conversion of extracted values into target data types, error checks, flagging of erroneous records, and hash value computation can all be implemented as generic stored procedures that build the appropriate dynamic SQL statements from metadata. This requires upfront investment in implementing those procedures. Once they exist, the tasks above reduce to simple procedure calls. In the long run, this reduces development effort and maximizes reuse.
Scope of the dynamic part. Dynamic SQL in the strict sense only appears in the data-quality check — one rule maps to one WHERE clause applied to the typed table at run time. Beyond that, the procedures listed above (type conversion, DQ check, flagging, hash-value computation) are metadata-generatable, because they follow the same structural pattern for every target table. This generation covers the corridor from extraction up to technical historization (schema T2). From schema L1 onward — the structural transformation — the JOIN statements are target-system-specific and are developed manually; so are the historization procedures for schema L2 (see the corresponding sections below).
How these generic checks are implemented in practice is shown in Checking Data Quality with SQL — a configurable framework that handles the tasks listed above through metadata-driven procedures.
Historization of Technically Transformed Data
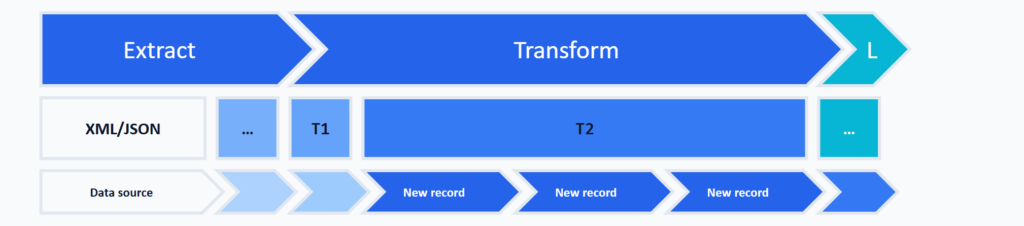
Historization consists of the following sub-steps:
- Historization
- Identification of change records
- Identification via hash values
- Storing hash values
- Promoting only error-free records
Historization
Historization means that delivered data is rolled forward in a database. In the data warehousing world, Slowly Changing Dimensions describes several types of historization that specify exactly how the rolling-forward works. Slowly Changing Dimensions is also commonly abbreviated as SCD. Ralph Kimball‘s canonical typology covers six types (SCD 1 through SCD 6); some sources additionally describe Type 0 (attributes that never change) and Type 7 (hybrid of surrogate and natural keys). Only two of these types are relevant here:
- SCD 1 — strictly speaking, no real historization at all. A record loaded earlier is simply overwritten by its changed counterpart. Only the most recent state of each record is ever stored.
- SCD 2 — every table that historizes data gets two extra columns ValidFrom and ValidTill, indicating the validity interval of the record. Currently valid records are open-ended, indicated for example by NULL in ValidTill. When a change record arrives for a currently valid record, the previously valid record’s ValidTill is set to the date from which the change record becomes valid, and the change record itself is inserted with ValidTill = NULL.
Historization is optional. With delta loads it can be helpful or even required, however. Suppose a customer places a new order. In a delta load, the order is delivered, but not the customer (who has not changed). Resolving the foreign-key relationship between order and customer cannot be done from the delivered data alone. To resolve it, either the customer data has to be extracted from the target system, or customers must be historized in the staging database so they are available on subsequent ETL runs.
In the context of the ETL process presented here, historization means that only error-free, changed records are historized. Historization can follow either SCD 1 or SCD 2.
Identification of Change Records
Historization requires being able to recognize change records in the source system and, subsequently, in the historized tables. Source systems often provide no information — or only unreliable information — about when a record was inserted, modified, or deleted. When a CSV file is generated from a hand-edited EXCEL document, for example, we can take it for granted that no reliable change information is available. Against that backdrop, this design pattern always derives change records from the data itself. The hash values computed during the Technical Transformation are used for this.
Identification via Hash Values
In the Technical Transformation section, hash values were computed for error-free records — one over the business-key columns, one over the remaining columns. Both can be used to identify change records. New, modified, and deleted records can be identified by comparing the hashes of the business key and the attributes between the tables holding the extracted data (schema T1) and the historized data (schema T2):
| Hash (business key) | Hash (attributes) | Type of change |
|---|---|---|
| present in T1 and T2, equal | equal | no change |
| present in T1 and T2, equal | not equal | record was modified |
| only in T1 (extracted) | — | new record |
| only in T2 (historized) | — | record was deleted |
Storing Hash Values
When a new record is inserted into the historized tables, updated, or flagged there as deleted, the hash values of the new, modified, or deleted record are stored or updated accordingly. This ensures that the hash values stored there always represent the status quo of the source systems and that change records can be identified via hash values at any later point (in subsequent ETL runs).
Promoting Only Error-Free Records
Promoting an erroneous record — and later loading it into the target system — could cause an error and potentially abort the entire ETL run. Therefore, only error-free change records from schema T1 are stored in schema T2.
Structural Transformation

The structural transformation consists of the following sub-steps:
- Structural transformation and resolution of foreign-key relationships and lookup values
- Structural data quality check
- Data error logging
- Flagging of erroneous records
- Hash value computation
Structural Transformation and Resolution of Foreign Key Relationships and Lookup Values
The output of the structural transformation is data in table structures matching the target system. The structural transformation is implemented as SQL statements with the required JOINs in the FROM clause. Developing those statements requires solid knowledge of the data, the relationships among entities, and especially the foreign-key relationships among tables in the source system — or among the source systems being integrated.
Besides the actual structural transformation of source data, the structural transformation resolves foreign-key relationships for the target system and determines the codes to store for lookup values. The result is stored in tables of schema L1, whose structure, column names, and data types resemble those of the target system.
Structural Data Quality Check
After the structural transformation, the result is checked: could all foreign-key relationships and lookup values be resolved? If no foreign key or no lookup code can be determined for a record, the record counts as erroneous. Since this check concerns the outcome of the structural transformation, it is called the structural data quality check here.
Data Error Logging
Detected data errors are logged in a readable, queryable form in an error table.
Flagging of Erroneous Records
If a record contains at least one error, it is flagged as erroneous so it can be excluded from further processing. The flag lives in a column that stores the count of detected errors. Error-free records carry NULL in this column.
Hash Value Computation
The last sub-step of the structural transformation is computing two hash values per record. The first hash represents the business-key columns of a structurally transformed record; the second hash represents all remaining attribute columns. Both hashes let the next work package — Historization of Structurally Transformed Data — identify change records.
Historization of Structurally Transformed Data
Historization of the structurally transformed data covers the same sub-steps as historization of the technically transformed data. It is an optional step, because — as long as the data from the technical transformation is historized — the structurally transformed data can always be reconstructed by running the structural transformation again.
Historization of the structurally transformed data takes the records from tables in schema L1 and stores them in tables of schema L2. The approach is identical to historizing data from schema T1 into schema T2. Only error-free change records are historized from L1 into L2. New, changed, and deleted records are additionally marked with a flag indicating that they still need to be loaded into the target system. If the data of schema L2 is historized as well, it must never be deleted and should be backed up by a maintenance process. This way, it is always possible to trace when which record changed.
The procedures required to historize data into schema L2 must be developed manually.
Loading

The transformed and quality-checked data in schema L2 can now be loaded into the target system using a technology of choice. The change records to be loaded are identified via a flag indicating whether the record has already been loaded. Records loaded successfully into the target system are flagged accordingly.
FAQ
The technical transformation works on each record in isolation: it converts input values into the target data types (text → date, decimal, …) and runs a first data-quality check at the value level, both without looking at other tables. The structural transformation, by contrast, needs context from the target system — resolving foreign keys, mapping lookup values — and therefore happens in its own work package after the technical transformation. Splitting them lets the two classes of errors be logged and fixed separately.
Materialization — writing each work package’s output to a database table — decouples three things: the source system is read only once and runs unobserved by downstream steps; every step becomes re-startable without rerunning the entire ETL pipeline; and a traceable audit trail emerges for diagnosing errors on individual records. The storage overhead is negligible compared with the robustness gained.
Not strictly. The full E0/E1/T1/T2/L1/L2 layering pays off mostly where audit trail, per-package restartability, and after-the-fact error analysis are hard requirements — typically in classical migration and CRM-integration projects with data volumes in the low to medium range (≤100M records per run). For large volumes or modern platforms such as Snowflake, Databricks, or BigQuery, some intermediate layers are often implemented as views rather than materialized tables — the architectural logic stays the same while storage and I/O overhead drop. Rule of thumb: T2 and L1 are the first candidates for virtualization, because they can always be reconstructed from T1 and T2 respectively.
Historization pays off when the ETL process handles delta loads — that is, only the changes since the last run, not a full snapshot. In a delta load, the order record is delivered but not the related customer (if the customer has not changed); without historized customer data, the foreign-key relationship cannot be resolved. With full snapshot loads — where every run pulls the entire source system — SCD is optional and usually unnecessary.
The core concepts of the pattern — work packages, schema layering E0–L2, data quality at the boundaries, hash-based SCD — are not tied to SQL Server and can be implemented in any relational database. The code presented here, however, is consistently T-SQL / SQL Server-centric (SSIS, OPENXML, OPENJSON, HASHBYTES, metadata-driven stored-procedure generation). The most important Postgres equivalents are: xmltable() for XML, jsonb_to_recordset() or JSON_TABLE (from Postgres 17) for JSON, and digest(…, 'sha256') from pgcrypto for hashes. Structural adaptation can go deeper than just renaming functions — for example, the E0/E1 split for XML/JSON can often be dropped in Postgres because xmltable() extracts directly from the source read.
There are clear similarities — business key, hash-based delta detection, layer separation into Raw / Cleansed / Business, auditability. Readers familiar with Data Vault will recognize E1/T2 as a “Raw + Hub/Satellite-equivalent” and L1/L2 as the “Business Vault”. The pattern presented here is, however, lighter: no strict Hub/Link/Satellite separation, no mandatory insert-only history, no Raw-Vault-vs-Business-Vault architectural dogma. For classical migration and CRM-integration projects with audit requirements, this simplification is pragmatic; for pure data-warehouse loading with multi-source integration, Data Vault 2.0 is worth a look.
Related Articles
- Data quality in an ETL process — root of the article series.
- Checking Data Quality with SQL — a Configurable Framework — the implementation layer beneath this architecture: spotting bad data generically and classifying it by severity.
- Design Pattern // Logging an ETL process with T-SQL — cluster sibling covering the logging layer.
- Design Pattern // Safe Type Conversion with T-SQL —
fn_try_convert_*UDFs for the technical transformation. - Data Quality // Fundamentals of Type Conversion with T-SQL — foundational article on
TRY_CONVERT. - ETL vs. ELT — How to Tell Which Pattern You Actually Built — classifies the architecture presented here as persistent-staging ELT.