How this articel has developed…
SQL Server Integration Services (SSIS) is a very powerful graphical tool set belonging to the Microsoft BI Stack along with SQL Server, SQL Server Analysis Services (SSAS), SQL Server Reporting Services (SSRS), etc. It supports a broad variety of data migration, integration and transformation tasks. With that, you will find a bunch of good reasons why to utilize this tool set. However, there are a plenty of reasons why not to use SSIS. With Transact SQL (T-SQL) Microsoft provides with respect to transformation tasks an equivalent technique.
This article belongs to a series of articles that are dealing with some important criteria for choosing the right technology(ies) – SSIS and/or T-SQL.
—
It is easy to identify differences between two versions of a development artifact, when this artifact was developed in a programming language like C#.NET, VB.NET, but also SQL. In contrast, the comparison of two versions of an SSIS package is everything but easy.
Even minor modifications to a SSIS package will result in a confusing number of modifications to the underlying XML document. To be honest, it is nearly impossible to identify even minor differences. Have a look also at the article SSIS vs. SQL – Source Control Management.
To demonstrate this issue, I planned to develop a halfway meaningful example. Wouldn’t it be interesting to find out whether there is an interdependence between the number of sick leave hours and the hierarchy level of an employee? That was the basic idea. Based on the table [AdventureWorksDW2017].[DimEmployee] I wanted to extract the hierarchy level of each employee and then calculate a ranking within each level ordered by the number of sick leave hours and vacation hours. The ranking should be equivalent to the T-SQL windowed functions NTILE() and DENSE_RANK().
I started with a T-SQL script and found a straightforward approach using a Common Table Expression (CTE) allowing recursive queries and the above-mentioned functions. To have an equivalent example in SSIS I started to develop the SSIS solution in the believe that it is as easy as the T-SQL solution was. But it was not.
There were two major requirements:
- Determination of the hierarchy levels of employees
- Calculation of the rankings
For both requirements there are IMHO no simple solutions or even approaches available in SSIS. I had the idea, that developing a recursive query by SSIS means could impose a problem to the solution. But I was somewhat puzzled to learn that there is no way to calculate rankings equivalent to DENSE_RANK() or NTILE() by SSIS means.
I hope that my final SSIS solution (shown in this article) appears to be straight and coherent. However, the solution is not a recursive solution and is limited to 5 hierarchy levels. Initially, I planned to calculate the ranking by using expressions. But after two or three hours of intense search in the web I gave up that idea and calculated the ranking in Script Tasks.
While developing the SSIS solution I got struck by that question the more often as time was passing by without having a result:
Why don’t you extract the data in a Data Source Task by passing the SQL statement to the command text?
– or –
How much of SQL you want to have in your SSIS package?
In this article I want to present three possible solutions and discuss the above questions:
- Extract data by using a complex SQL statement in a Stored Procedure
If you are familiar with recursive Common Table Expressions the SQL statement for the extraction of the required data is a medium complex statement. This approach is based on a Stored Procedure executing this SQL statement and inserting data into a destination table. The Stored Procedure will be executed by a SQL Command Task in a SSIS Control Flow. One SQL statement, one Stored Procedure, one Control Flow, nothing else. - Extract data by using a complex SQL statement in a Data Source Task
Instead of providing the SQL statement in a Stored Procedure, the second approach utilizes the SELECT part of the statement in a Data Source Task of a SSIS Dataflow. This solution writes data to the destination table using a SSIS OLEDB Destination Task. One Control Flow, one Dataflow with two Dataflow Tasks, nothing else. - Use simple SQL in a Data Source Task
The third approach tries to omit SQL statements in favor of doing the transformation in terms of SSIS tasks. The presented SSIS solution relies on a temporary table, one Control Flow, 2 Data Flows and a bunch of Data Flow Tasks which are linked by complex Conditional Split tasks and precedence constraints.
These three solutions will be evaluated with respect to the following issues:
- Development Time
- Readability
- Maintainability
- Performance
- Functionality
Approaches
This section presents the three mentioned solutions. All solutions were developed with Microsoft Visual Studio 2017 and SQL Server 2017.Extract data by using a complex SQL statement in a Stored Procedure
Extract data by using a complex SQL statement in a Stored Procedure
This solution is based on a Stored Procedure [dbo]. [sp_post0022_InsertData] containing a complex SQL statement that utilizes a recursive Common Table Expression. The statement writes the data to the destination table [dbo].[Post00220001] and truncates the data in advance. The procedure will be finally called by an SSIS Execute SQL task.
Note
The screenshots are taken from the German article, that is internally organized as post0021. So, do not worry because of the diverging object names.

Extract data by using a complex SQL statement in a Data Source Task
The second solution is based on an SSIS data flow that contains nothing else than an OLE-DB source task and an OLE-DB destination task.
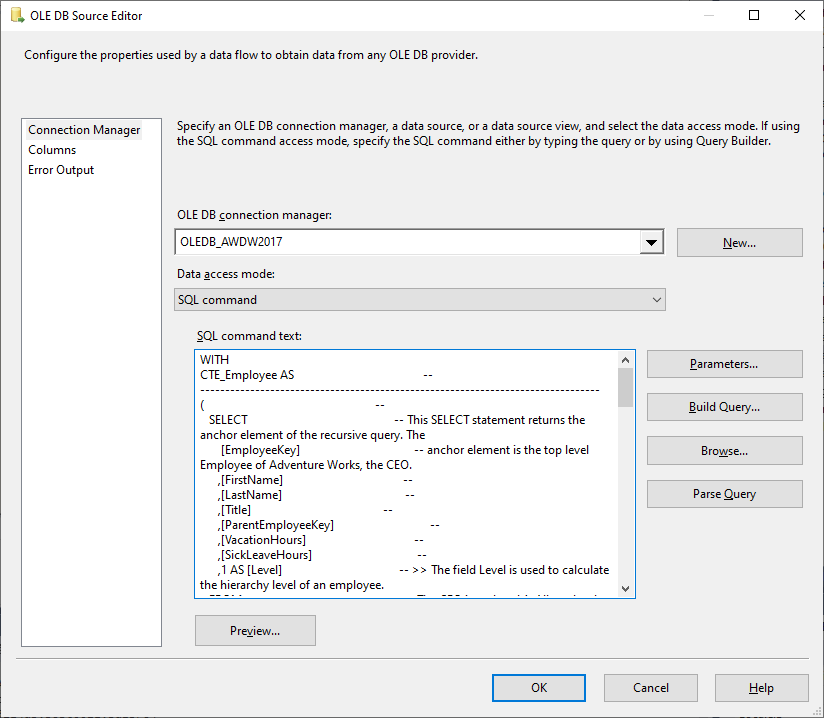
The data source task defines the data source as an SQL statement …the above-mentioned complex SQL statement mentioned above but without the INSERT INTO part.
There are no transformations in the data flow.
Use simple SQL in a Data Source Task
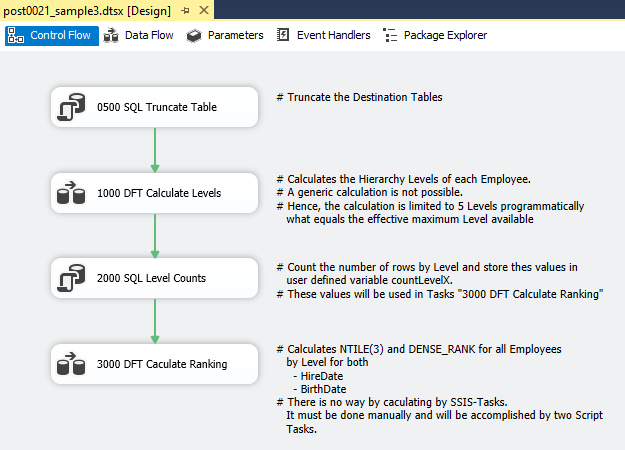
The third solution uses only SSIS tasks for the calculation of the hierarchy levels as well as the ranking. The solution includes a control flow, two data flows and two tables. The control flow contains 2 SQL tasks and 2 data flow tasks as followed:
- 0500 SQL Truncate Table
Truncates both temporary tables: [dbo].[post00210003] and [dbo].[post00210004]. - 1000 DFT Calculate Levels
This Dataflow calculates the hierarchy levels for all employees. The calculation is unlike the first solution not a generic calculation and limited to 5 hierarchy levels. - 2000 SQL Level Counts
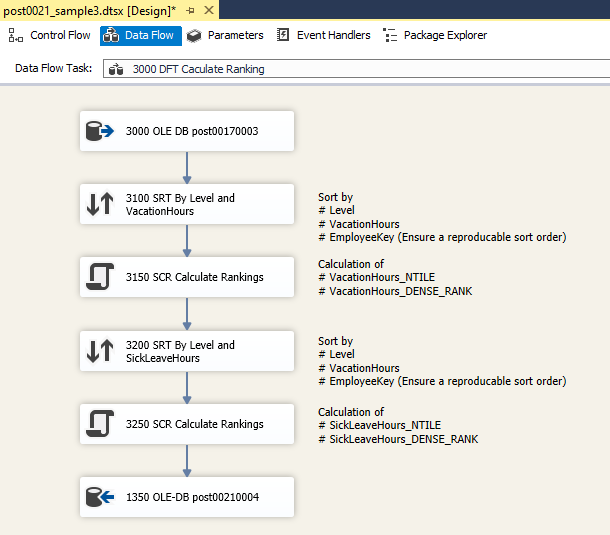
The calculation of the NTILE ranking requires the knowledge of the number of employees by hierarchy level. This Execute SQL Task executes 5 SQL statements that write the number of employees by hierarchy level to variables. - 3000 DFT Calculate Ranking
Finally, the calculation of the ranking itself is done in a Script Tasks. The result will be written to the table [dbo].[post00200004].
Control Flow
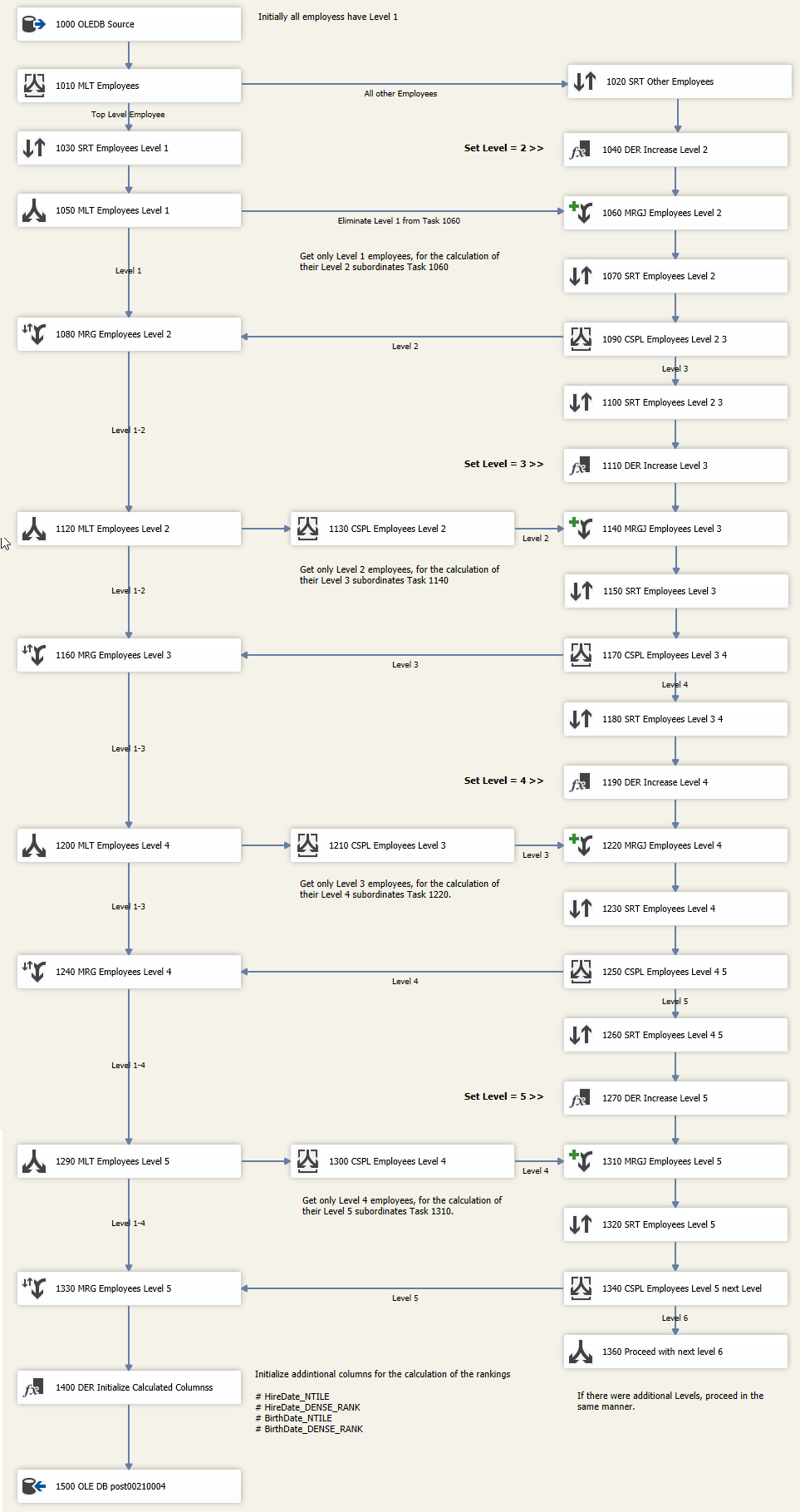
Data Flow: 1000 DFT Calculate Levels
The data source 1000 OLEDB Source specifies just a plain SQL SELECT statement without any transformation commands.
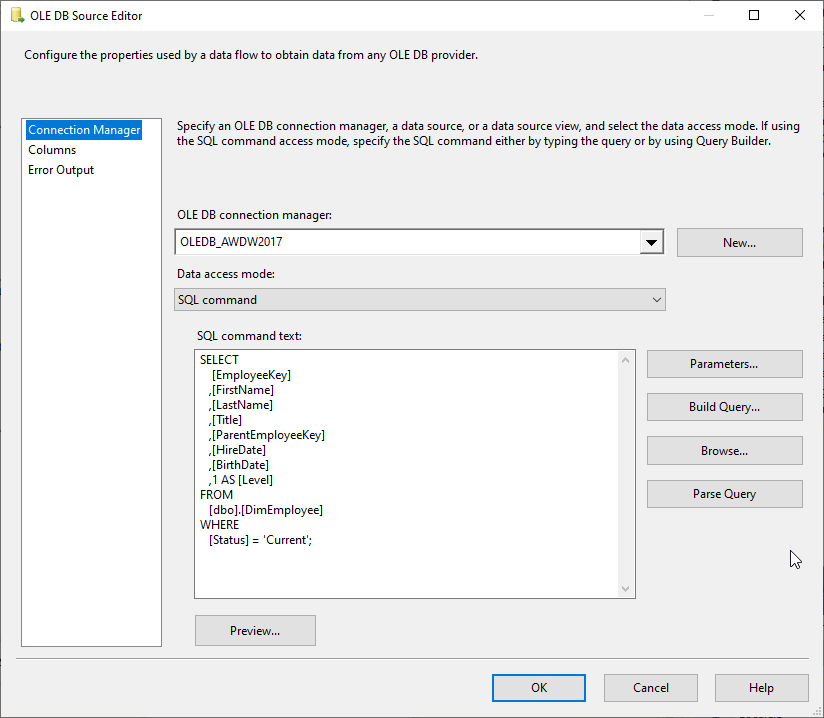
Data Flow: 3000 DFT Calculate Ranking
Evaluation
Time for development
Extract data by using a complex SQL statement in a Stored Procedure
As mentioned above, there are two challenges: Identifying the hierarchy levels of employees and identifying their ranking. For both challenges, T-SQL offers a more or less easy to use concepts allowing for fast development. Using the concept of recursive common table expressions (CTE), hierarchically structured data can be queried with little effort and virtually no limitation with respect to the hierarchy levels. With the windowed functions NTILE() and DENSE_RANK() also the second challenge is implemented with only a few lines. The SQL statement is created in just a few minutes and saved within a Stored Procedure.
Extract data by using a complex SQL statement in a Data Source Task
The second approach uses the same complex SQL Statement as described in the above section as the data source in a data source task. This SSIS package contains only two data flow tasks: one data source task and one data destination task. No more transformations tasks are required. The essential effort results from the creation of the SQL statement. As explained in the previous section, the statement is created in just a few minutes. The SSIS package itself was developed with minimal effort.
Use simple SQL in a Data Source Task
The third approach utilizes just standard SSIS control flow tasks and data flow tasks for both the calculation of the hierarchy levels and the ranking. The data source task of the data flow contains just a simple SELECT statement. All transformations are carried out via SSIS data flow tasks. In contrast to T-SQL, there is no ideal solution here. In fact, it was a fallacy to believe that the two challenges can be solved equally comfortably by SSIS means. For the non-generic determination of the hierarchy levels and the determination of the ranking, more than 40 data flow tasks had to be configured and connected with complex precedence constraints and join tasks/split tasks. The development took a few hours.
Summary
In this example, the requirements are implemented much faster with T-SQL than with (only) SSIS. While in T-SQL the approach is more or less dictated, the approach in SSIS had to be designed first. The effort for developing the SQL statements represented only a fraction of the time needed for the development of the SSIS solution.
The more SQL statements are utilized in a SSIS package, the faster the development will be.
Readability
Extract data by using a complex SQL statement in a Stored Procedure
The actual SQL INSERT statement of the first solution covers a maximum of 80 lines when structured generously. With a reasonable structure and formatting of the statement, the chosen solution can be quickly grasped. The statement of the first screenshot is easy to read.
Extract data by using a complex SQL statement in a Data Source Task
The second solution partly uses the SQL statement of the stored procedure [dbo].[spInsertPost0022] of the first approach. While the SQL statement itself is easy to understand, it is difficult to read when placed in the SQL command text field of the data source task. There are two reasons for this: On the one hand, a proportional font is used to display the SQL statement, and on the other hand, the field is nothing more than a peephole. Complex statements are difficult to read using this dialog.
Use simple SQL in a Data Source Task
In the third approach based on SSIS, a simple SQL statement was defined as the data source. The complexity of this approach lies in the more than 40 data flow tasks. While a SQL statement can be read from top to bottom, extensive actions are required when reading a complex SSIS package. All tasks must be opened; their configuration must be checked. A large proportion of the logic is represented by precedence constraints and join tasks. The complex solution design was associated with far more effort than the development of the complex SQL statements.
Summary
A well structured and formatted SQL statement is much more readable than pure SSIS approaches that perform the same task.
The degree of readability also depends on where the SQL statement is saved and in which “editor” the statement is displayed by default. While a procedure or statement in SQL Server Management Studio is easy to read, it is not in the dialog of the data source task.
Maintainability
Readability
Maintainability is strongly linked to readability. Troubleshooting in plain SQL statements requires much less effort for troubleshooting in comparison to troubleshooting SSIS packages that contain a bunch of SSIS tasks. While bugs are easily fixed in SQL statement, fixing a bug in an SSIS package may require a complete reengineering of a package.
Future modifications
Maintainability is also linked to future change requests. The evaluation of future efforts for change requests can not be answered as straight as the above-mentioned aspects.
The number of hierarchy levels in the dimension [AdventureWorksDW2017].[DimEmployee] is limited to 5. If, one day, employees were structured in 6 hierarchy levels there would be no additional effort for approach 1 (complex statement). No matter how deep the hierarchy is, the SQL statement would return (considering the technical limitation to 32,767 recursions within a recursive common table expression) the appropriate data. Extending the third approach by a 6th or even more hierarchy levels will result in a significant additional effort for the adaptation of the SSIS package. Per hierarchy level it would be necessary to add 8 additional data flow tasks including the precedence constraints. The additional effort can be even dramatically high if a complex SSIS data flow must be changed somewhere in the middle. In some cases, all dataflow tasks, that follow the modified task, must be deleted and redeveloped.
However, there are also circumstances where SSIS packages appear much more maintainable regardless of their complexity. Think of a switch of the database provider, e.g. from SQL Server to Oracle. Each database provider provides a proprietary SQL dialect: T-SQL in SQL Server an PL-SQL for Oracle. There is no guarantee, that a complex SQL statement developed for SQL Server can be executed in Oracle. The likelihood that a complex statement can be executed in both database management systems equally is nearly zero. In the worst case, a statement can not be adapted or only with extensive effort to the dialect of the new database management system.
A future change of the platform means for approach 3 – provided that the database provider is supported by SSIS – that there is almost no need for a functional change of the SSIS package. The data source task utilizes a simple SQL statement that can be interpreted by both providers. The only required adaption is the modification of the connection of the data source task and data destination task.
Compare two versions of an artifact
A prerequisite for the development of maintainable artifacts is the versioning of the artifacts in a source code management. A developer must be able to identify the code in the repository for each delivered and installed version of software or an ETL process. In the event of an error, changes to the code must be traced back so that errors can be identified. Which version of an artifact failed? What has changed from version to version? Comparing the failing artifact with the last deployed version usually leads to a quick answer. More thoughts on comparing two versions of artifact you can find in the article SSIS vs. SQL – Source Code Management. As a result, this article finds that two versions of an SSIS package are simply not comparable. From this point of view, SSIS packages are difficult to maintain.
Summary
Most developers use more or less complex SQL statements in SSIS data source tasks. This is because developing even simple transformations such as JOINs can be challenging. From the point of view of maintainability, the question should then be allowed, why is a statement placed within the data source task?! Wouldn’t it be better to pack the statement in a view, a stored function or a stored procedure? In this case, the view, the stored function or the stored procedure can be quickly transferred as a SQL script to a Visual Studio database project using a Schema Compare and the script can be checked into a source code management system.
When assessing the advantages and disadvantages of SQL compared to SSIS from the point of view of maintainability, the assessment is clearly in favor of SQL, too.
However, there is a small exception: When thinking of future modifications due changes in the infrastructure (other database providers, distributed environment, etc.), the advantages and disadvantages of the two technologies must be weighed up in detail.
Performance
There are numerous factors that can influence performance and must be considered when making a reliable comparison. For the sake of simplicity, I do not take these factors into account, in order to ultimately be able to substantiate my conviction with the execution times I measured: SSIS is slower than T-SQL if an SSIS package contains even simple transformations that result in asynchronous data processing and that could be implemented in a SQL statement without problems.
An example of this is the simple joining of tables. In SSIS, a data flow must be sorted before it can be used in a join task. Sorting means that the data flow can no longer be processed asynchronously. The synchronous data processing of a join in SSIS is undoubtedly slower than the processing within a SQL statement in SQL Server. Approach 3 (SSIS only) presented in this article is about 2 times slower than approach 1 (SQL only).
I am aware that this is an extremely undifferentiated statement. For the sake of completeness, however, it should be mentioned that there are also tasks that perform much better in SSIS than an SQL statement.
Summary
In general, the undifferentiated statement can be made that complex transformations developed in SSIS perform more slowly than a pure SQL implementation.
Functionality
This article deals with a task that, among other things, impressively shows how different the performance of the selected technologies in terms of time for development, readability and maintainability is. What can be solved with a comparatively simple SQL statement requires a rather complex approach with SSIS. This is not supposed to be a fundamental plea for T-SQL. There are a lot of requirements that cannot be solved with T-SQL or that are not so easy. SSIS is far more flexible regarding data sources, parallelization, file operations and many other aspects.
Summary
If a task can be solved with simple or complex TSQL, it can and should be processed with T-SQL. In all other cases, of course, SSIS comes into play.
Source code
The examples shown here were developed in Visual Studio 2017 in connection with a SQL Server 2017 database. The source code for the example can be downloaded from the following link:
Summary
Regarding the development time, readability and maintainability, the choice is easy. The more SQL, the faster, more readable, and maintainable is an SSIS package. With a view to the range of functions, only a differentiated assessment can provide the correct answer. The calculation of rankings and hierarchy may be easier with T-SQL. The development and performance of a fuzzy search, on the other hand, will be much faster in SSIS.
The assessment of the performance must take different scenarios of data processing into account. There are areas of application in which SSIS performs better than T-SQL. Whenever it comes to asynchronous data processing – if data can already be written while the data to be written is still being read – SSIS should be preferred.
Despite its length, this article answers the question How much of SQL you want to have in your SSIS package? only superficial and in parts very undifferentiated. With this article I do not want to present an absolute opinion. The article should serve as a suggestion to always examine the scope of the use of SSIS critically.
As further reading I can recommend the article The Hidden Costs of SSIS: The Hidden Costs of SSIS: How to Avoid SQL Server Integration Services Gotchas by Michael K. Campbell, which describes the pros and cons when choosing the better technology.