Ein SSIS-Paket schlägt fehl, du öffnest das Ausführungsprotokoll, um die Ursache zu finden — und stehst vor einer Baumstruktur, in der die Tasks nicht in der Reihenfolge ihrer Ausführung stehen, sondern alphabetisch nach Namen. Bei komplexen Paketen wird dieses Protokoll schlicht unlesbar. Die gute Nachricht: Eine durchdachte Namenskonvention löst das Problem vollständig — ganz ohne Code.
Das Wichtigste vorab:
- Das Problem: SSIS protokolliert Tasks alphabetisch nach Task-Namen je Container, nicht in Ausführungsreihenfolge — im Reiter Progress wie auch in den Integration-Services-Catalog-Reports.
- Nummerierung als Präfix bringt die Tasks im Protokoll in ihre echte Ausführungsreihenfolge.
- Typ-Präfix (
DFT,SQL,SCR, …) macht den Task-Typ im rein textuellen Protokoll erkennbar. - Sprechender Name + die Gesamt-Syntax
XXXX [YYYY] ZZZ Namemachen jeden Task-Namen eindeutig und selbsterklärend. - SSIS heute läuft über die VS-2022/2026-Extension — die Konvention bleibt gültig, und ihr Prinzip überträgt sich auf moderne ETL-Tools (Azure Data Factory, Fabric, dbt, Airflow).
Voraussetzung: ein SSIS-Projekt in Visual Studio (mit der SQL Server Integration Services Projects-Extension). Die Screenshots stammen aus Visual Studio 2017; die Konvention gilt versionsunabhängig.
Warum SSIS-Tasks eine Namenskonvention brauchen
Die Festlegung von Programmierrichtlinien und Namenskonventionen ergibt nur dann Sinn, wenn sie gewinnbringend eingesetzt werden können. Voraussetzung dafür ist, dass die Vorteile klar benannt werden können. Lesbarkeit und Wartbarkeit von Code stehen meist im Vordergrund. Im Falle von SQL Server Integration Services (SSIS) kommt jedoch noch ein weiterer Aspekt hinzu: die Protokollierung der Ausführung eines Paketes in dem Reiter Execution Results bzw. Progress in der Entwicklungsumgebung Visual Studio. Die Ausführung wird in einer Baumstruktur protokolliert. Bei komplexen Paketen mit Unterpaketen, For Each Loop Containern, Sequence Containern etc. wird die Baumstruktur schnell lang und tief. Es ist schwer, die Ausführungsreihenfolge der Tasks in der Baumstruktur nachzuvollziehen und im Fehlerfall die Fehlerursache schnell zu identifizieren. Wer ist nicht schon an dieser vermeintlich einfachen Aufgabe verzweifelt?!
Ursächlich hierfür ist aber nicht die Komplexität eines Paketes oder die Schachtelungstiefe. SSIS zeigt die ausgeführten Tasks nicht in der Reihenfolge der Ausführung an. Die Anordnung von ausgeführten Tasks in der Baumstruktur erfolgt in alphabetischer Reihenfolge der Task-Namen je Container.
Der nachfolgende Screenshot zeigt einen vermeintlich übersichtlichen Control Flow nach einer Ausführung in Visual Studio 2017:

Zu beachten sind hier:
- Die Namen der Sequence Container sind so gewählt, dass der Container mit dem Suffix 2 vor dem Container mit dem Suffix 1 ausgeführt wird.
- Innerhalb der Sequence Container sind die enthaltenen Control Flow Tasks so benannt, dass die Tasks mit dem Präfix 2 vor den Tasks mit dem Präfix 1 ausgeführt werden.
- Zwischen den beiden Sequence Containern werden 3 Skript Tasks ausgeführt, die durch die Präfixe C, B und A entgegen der Ausführungsreihenfolge benannt sind.
Die beiden Data Flows enthalten identische Data Flow Tasks. Die Tasks sind so benannt, dass sie entgegen der alphabetischen Sortierung nach dem Task-Namen ausgeführt werden. Zuerst wird die Task OLE-DB Source ausgeführt und danach erst die Task Count.
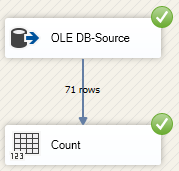
Die Ausführung der Control und Data Flow Tasks wird in dem Reiter Progress des ausgeführten Paketes nicht in der Reihenfolge der tatsächlichen Ausführung, sondern in der Reihenfolge der alphabetischen Sortierung der Task-Namen je Container protokolliert:
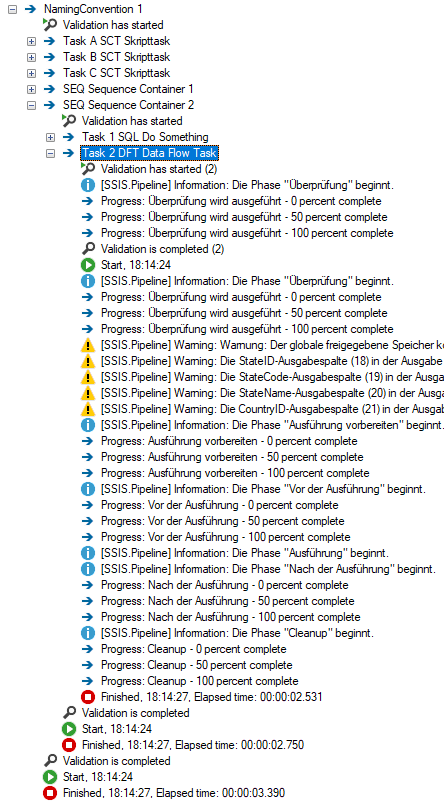
Bei umfangreichen und komplexen Transformationsprozessen ist dieses Ausführungsprotokoll schlicht unlesbar. Warum Microsoft diese Systematik gewählt hat, ist nicht nachvollziehbar. Nun sind die gezeigten Screenshots bzw. die gewonnenen Erkenntnisse eher für die Entwicklung von SSIS Paketen relevant. Wie sieht es im Betrieb von SSIS Solutions aus, wenn diese in dem Integration Services Catalogs bereitgestellt und ausgeführt werden? Das Ausführungsprotokoll eines im Integration Services Catalogs bereitgestellten Paketes kann über die Standard-Berichte
Rechtsklick auf Projekt/Paket > Reports | Standard Reports | All Executions
aufgerufen werden. Und tatsächlich wird auch hier die Ausführung von Tasks nicht entsprechend der tatsächlichen Ausführungsreihenfolge protokolliert:
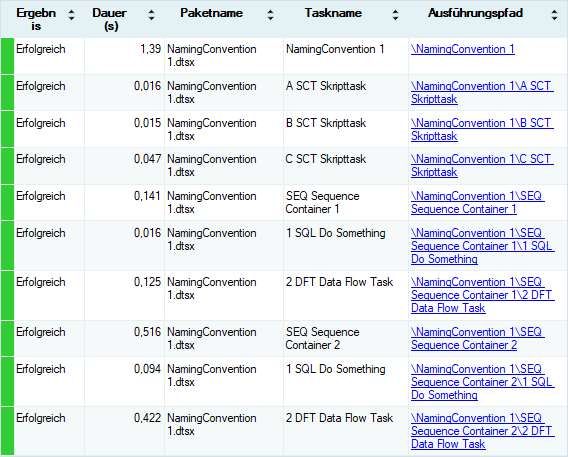
Aus den gewonnenen Erkenntnissen ergibt sich die Forderung nach einer Benennung von Tasks, die eine korrekte – der Reihenfolge der Ausführung von Tasks entsprechende – Protokollierung von Tasks sicherstellt. Es gibt zwei weitere weit verbreitete Namenskonventionen, die die Lesbarkeit von Paketen sowohl zur Entwurfszeit aber auch die Lesbarkeit des Protokolls zur Laufzeit erhöhen.
- Nummerierung aller Tasks entsprechend der Ausführungsreihenfolge
- Präfix für jeden Task-Typ
- Task-Name beschreibt das, was die Task macht
Nummerierung aller Tasks entsprechend der Ausführungsreihenfolge
Bei der Nummerierung von Tasks ist zwischen der Nummerierung von Control Flow Tasks und Data Flow Tasks zu unterscheiden.
Control Flow Tasks
Alle Tasks sollten über eine aufsteigende Nummerierung als Präfix verfügen, die in aufsteigender Reihenfolge der Ausführungsreihenfolge entspricht. Die Nummerierung sollte einen vierstelligen Nummernkreis unterstützen (also Nummern bis mindestens 9999) und bei kleineren Zahlen führende Nullen aufweisen. Die Nummerierung sollte keineswegs geschlossen sein, also noch Lücken aufweisen, damit die Reihenfolge der Ausführung durch Änderung der Nummerierung einfach geändert werden kann. Natürlich ist die Nummerierung von Tasks mit Aufwand verbunden. Aus der Erfahrung aus Mehrentwicklerprojekten kann ich aber berichten, dass diese Namenskonvention weithin akzeptiert und auch gewinnbringend angewandt wurde.
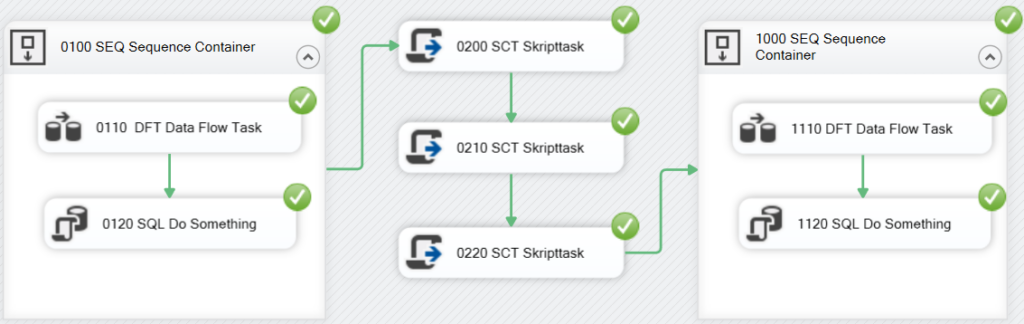
Das folgende Ausführungsprotokoll listet die Tasks in der Reihenfolge ihrer Ausführung auf und ist damit ungleich lesbarer als die erste Version:
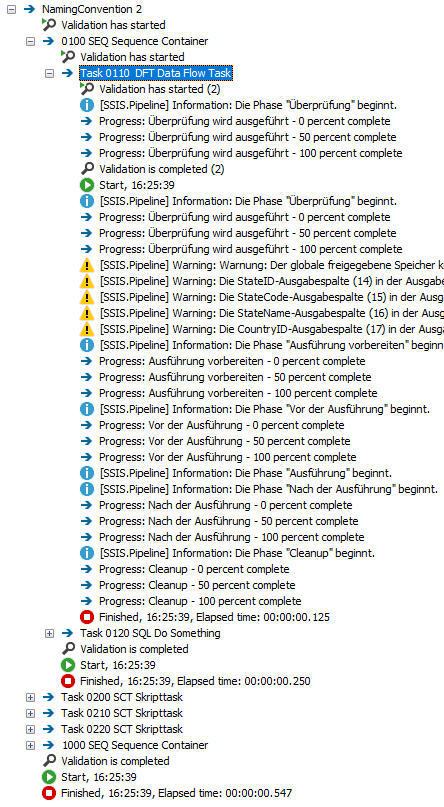
Data Flow Tasks
In dem normalen Ausführungsplan sind Data Flow Tasks nicht enthalten. Trotzdem ist es ratsam die oben beschriebene Systematik der Benennung von Tasks auch in Data Flows beizubehalten bzw. sogar noch zu erweitern:
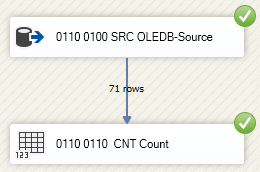
Die erste ausgeführte Data Flow Task hat als Präfix die Nummer 0110. Dieses Präfix ist für alle Data Flow Tasks zu verwenden gefolgt von einer weiteren Nummer, um die Tasks in dem Data Flow eindeutig identifizieren zu können. Damit werden jedem Data Flow Task-Namen zwei Nummern vorangestellt.
- Control Flow Nummer
- Data Flow Nummer
Im Fehlerfall wird schließlich auch der Task-Name der Data Flow Task protokolliert, die einen Fehler verursacht hat. Die Vergabe eindeutiger Nummern ermöglicht eine zweifelsfreie und vor allem schnelle Identifikation der Fehler verursachenden Task:

Präfix für jeden Typ einer Task
Jeder Task-Typ verfügt in Visual Studio über ein eigenes Piktogramm. Der stilisierten Darstellung von Task-Typen sind aber aufgrund der verfügbaren Größe der Piktogramme Grenzen gesetzt. Zudem handelt es sich hier um eine visuelle Darstellung, die in dem Ausführungsprotokoll nicht zur Verfügung steht. Die Unterscheidung der Tasks in dem Reiter Execution Results bzw. Progress erfordert daher eine Kennzeichnung über ein Präfix, das den Typ der Task identifiziert.
Um die Lesbarkeit zu erhöhen ist daher allgemein anerkannt, den Task-Namen in Abhängigkeit von dem Task-Typ ein Präfix bzw. eine Abkürzung voranzustellen:
- DFT für Data Flow Task
- SCT für Script Task
- SQL für SQL Execute Task
- …
Im Internet findet man einige Vorschläge für diese Präfixe. In den folgenden beiden Listen habe ich die von mir verwendeten Task Präfixen zusammengetragen:
Präfixe für Control Flow Tasks
| Task | Präfix |
| Back Up Database Task | BACKUP |
| CDC Control Task | CDC |
| Check Database Integrity Task | CHECKDB |
| Data Profiling Task | DPT |
| Execute SQL Server Agent Job Task | AGENT |
| Execute T-SQL Statement Task | TSQL |
| History Cleanup Task | HISTCT |
| Maintenance Cleanup Task | MAINCT |
| Notify Operator Task | NOT |
| Rebuild Index Task | REBIT |
| Reorganize Index Task | REOIT |
| Shrink Database Task | SHRINKDB |
| Update Statistics Task | STAT |
| For Loop Container | FLC |
| Foreach Loop Container | FELC |
| Sequence Container | SEQC |
| ActiveX Script | AXS |
| Analysis Services Execute DDL Task | ASE |
| Analysis Services Processing Task | ASP |
| Bulk Insert Task | BLK |
| Data Flow Task | DFT |
| Data Mining Query Task | DMQ |
| Execute Package Task | EPT |
| Execute Process Task | EPR |
| Execute SQL Task | SQL |
| Expression Task | EXPR |
| File System Task | FSYS |
| FTP Task | FTP |
| Message Queue Task | MSMQ |
| Script Task | SCR |
| Send Mail Task | SMT |
| Transfer Database Task | TDB |
| Transfer Error Messages Task | TEM |
| Transfer Jobs Task | TJT |
| Transfer Logins Task | TLT |
| Transfer Master Stored Procedures Task | TSP |
| Transfer SQL Server Objects Task | TSO |
| Web Service Task | WST |
| WMI Data Reader Task | WMID |
| WMI Event Watcher Task | WMIE |
| XML Task | XML |
Präfixe für Data Flow Tasks
| Task | Präfix | Type | Supplier |
| ADO NET Source | ADO_SRC | Source | |
| Azure Blob Source | AB_SRC | Source | |
| CDC Source | CDC_SRC | Source | |
| DataReader Source | DR_SRC | Source | |
| Excel Source | EX_SRC | Source | |
| Flat File Source | FF_SRC | Source | |
| HDFS File Source | HDFS_SRC | Source | |
| OData Source | ODATA_SRC | Source | |
| ODBC Source | ODBC_SRC | Source | |
| OLE DB Source | OLE_SRC | Source | |
| Raw File Source | RF_SRC | Source | |
| SharePoint List Source | SPL_SRC | Source | |
| XML Source | XML_SRC | Source | |
| Aggregate | AGG | Transformation | |
| Audit | AUD | Transformation | |
| Balanced Data Distributor | BDD | Transformation | |
| Cache Transform | CCH | Transformation | |
| CDC Splitter | CDCS | Transformation | |
| Character Map | CHM | Transformation | |
| Conditional Split | CSPL | Transformation | |
| Copy Column | CPYC | Transformation | |
| Data Conversion | DCNV | Transformation | |
| Data Mining Query | DMQ | Transformation | |
| Derived Column | DER | Transformation | |
| DQS Cleansing | DQSC | Transformation | |
| Export Column | EXPC | Transformation | |
| Fuzzy Grouping | FZG | Transformation | |
| Fuzzy Lookup | FZL | Transformation | |
| Import Column | IMPC | Transformation | |
| Lookup | LKP | Transformation | |
| Merge | MRG | Transformation | |
| Merge Join | MRGJ | Transformation | |
| Multicast | MLT | Transformation | |
| OLE DB Command | CMD | Transformation | |
| Percentage Sampling | PSMP | Transformation | |
| Pivot | PVT | Transformation | |
| Row Count | CNT | Transformation | |
| Row Sampling | RSMP | Transformation | |
| Script Component | SCR | Transformation | |
| Slowly Changing Dimension | SCD | Transformation | |
| Sort | SRT | Transformation | |
| Term Extraction | TEX | Transformation | |
| Term Lookup | TEL | Transformation | |
| Union All | ALL | Transformation | |
| Unpivot | UPVT | Transformation | |
| ADO NET Destination | ADO_DST | Destination | |
| Azure Blob Destination | AB_DST | Destination | |
| Data Mining Model Training | DMMT_DST | Destination | |
| Data Streaming Destination | DS_DST | Destination | |
| DataReaderDest | DR_DST | Destination | |
| Dimension Processing | DP_DST | Destination | |
| Excel Destination | EX_DST | Destination | |
| Flat File Destination | FF_DST | Destination | |
| HDFS File Destination | HDFS_DST | Destination | |
| ODBC Destination | ODBC_DST | Destination | |
| OLE DB Destination | OLE_DST | Destination | |
| Partition Processing | PP_DST | Destination | |
| Raw File Destination | RF_DST | Destination | |
| Recordset Destination | RS_DST | Destination | |
| SharePoint List Destination | SPL_DST | Destination | |
| SQL Server Compact Destination | SSC_DST | Destination | |
| SQL Server Destination | SS_DST | Destination | |
| Microsoft Dynamics 365 CE/CRM Source | CRM_SRC | Source | KingswaySoft Software |
| Microsoft Dynamics 365 CE/CRM Destination | CRM_DST | Destination | KingswaySoft Software |
| Oracle Eloqua Source | ELO_SRC | Source | KingswaySoft Software |
| Oracle Eloqua Destination | ELO_DST | Destination | KingswaySoft Software |
Task-Name
Zu guter Letzt… Natürlich sollte der eigentliche Task-Name kurz und knapp das beschreiben, was die Task macht. Zum Beispiel Import Customer, Check Data Types, usw.
Namenskonvention
Innerhalb eines SSIS-Paketes sollten alle Task-Namen — unabhängig davon, ob es sich um einen Control Flow Task oder einen Data Flow Task handelt — eindeutig sein. Die folgende Namenskonvention stellt das sicher und folgt dieser Syntax:
XXXX [YYYY] ZZZ Name
mit
XXXX
- Nummerierung der Control Flow Tasks.
- Die Nummerierung von Control Flow Tasks sollte 4-stellig sein.
- Bei kleinen Nummern sind führende Nullen voranzustellen.
- Die Nummerierung sollte Lücken aufweisen, um eine nachträgliche Änderung der Reihenfolge durch Veränderung der Precedence Constraints zu vereinfachen.
YYYY
- Nummerierung der Data Flow Tasks
- Die Nummerierung von Data Flow Tasks enthält als Präfix immer die Nummer der Control Flow Task vom Typ Data Flow (XXXX).
- Die Nummerierung von Data Flow Tasks sollte 4-stellig sein.
- Bei kleinen Nummern sind führende Nullen voranzustellen.
- Die Nummerierung sollte Lücken aufweisen, um eine nachträgliche Änderung der Reihenfolge durch Veränderung der Precedence Constraints zu vereinfachen.
ZZZ
- Präfix, der den Typ der Control Flow oder Data Flow Task identifiziert.
- Liste mit Präfixen (s.o.)
Name
- Kurze und bedeutungsvolle Umschreibung dessen, was die Aufgabe der Task ist.
SSIS heute: Tooling-Update und Einordnung
Die Screenshots in diesem Artikel stammen aus Visual Studio 2017 — die Konvention selbst ist seither unverändert gültig. Geändert hat sich das Tooling: SSIS-Pakete werden heute mit der separat zu installierenden Extension SQL Server Integration Services Projects 2022+ gebaut, die Visual Studio 2022 und 2026 unterstützt und Zielversionen von SQL Server 2017 bis 2025 abdeckt. Die Reiter (Progress / Execution Results) und die Integration-Services-Catalog-Berichte sind dieselben geblieben.
Versions-Hinweis: Das hier beschriebene Verhalten — Tasks im Protokoll alphabetisch nach Namen statt in Ausführungsreihenfolge — ist langjährige Praxiserfahrung (Stand der Screenshots: Visual Studio 2017). Microsofts Dokumentation beschreibt den Progress-Tab generisch als „in execution order“. Prüfe im Zweifel kurz in deiner SSIS-Version, ob die Sortierung noch greift — am Nutzen der Konvention ändert das ohnehin nichts.
Warum „ohnehin nichts“? Die drei Bausteine wirken unabhängig von der exakten Sortierreihenfolge: Eine Nummerierung macht das Protokoll scanbar, ein Typ-Präfix macht den Task-Typ im reinen Text erkennbar, und ein eindeutiger Name erlaubt im Fehlerfall die zweifelsfreie Zuordnung — egal, wie die Einträge angeordnet sind.
Wohin sich ETL bewegt
SSIS bleibt der etablierte On-Premises-ETL-Motor und wird weiter gepflegt. Für neue Projekte verschiebt sich der Schwerpunkt aber: In der Microsoft-Welt übernehmen Azure Data Factory und Microsoft Fabric die Cloud-Orchestrierung; im Open-Source- und Postgres-Umfeld haben sich dbt (Transformation) und Apache Airflow (Orchestrierung) etabliert. Die Grundidee dieses Artikels überträgt sich direkt: Auch dort entscheidet eine konsequente Benennung von Schritten und Modellen darüber, ob ein Lauf-Protokoll lesbar bleibt.
FAQ
SSIS sortiert die Tasks im Ausführungsprotokoll alphabetisch nach Task-Namen je Container — sowohl im Reiter Progress / Execution Results in Visual Studio als auch in den Berichten des Integration Services Catalogs. Die tatsächliche Ausführungsreihenfolge spielt für die Darstellung keine Rolle. Genau deshalb hilft eine Nummerierung als Präfix: Sie bringt die alphabetische Sortierung in Deckung mit der Ausführungsreihenfolge.
Jeder Data Flow Task bekommt zwei vierstellige Nummern vorangestellt: zuerst die Nummer der übergeordneten Control Flow Task vom Typ Data Flow, dann eine eigene Nummer innerhalb des Data Flows. So bleibt jeder Task auch im Fehlerprotokoll eindeutig identifizierbar. Beide Nummernkreise sollten Lücken lassen, damit sich die Reihenfolge später ohne Umbenennung aller Tasks ändern lässt.
Es gibt keine offizielle Microsoft-Vorgabe — die beiden Tabellen oben listen die verbreiteten, hier verwendeten Präfixe (DFT für Data Flow Task, SQL für Execute SQL Task, SEQC für Sequence Container usw.). Wichtig ist weniger die exakte Abkürzung als die teamweite Einheitlichkeit: Lege die Liste einmal verbindlich fest und halte dich konsequent daran.
Ja. Die Namenskonvention ist ein Baustein wartbarer SSIS-Lösungen neben der Protokollierung eines ETL-Prozesses, der Quellcodeverwaltung von SSIS-Paketen und der grundsätzlichen Abwägung SSIS vs. T-SQL bzw. wie viel SQL in ein SSIS-Paket gehört.