Overview
Capital letters are often used to emphasize single words. This applies, for example, to German as a language. Latin, Greek, … Although there are languages that do distinct between upper and lower case (with respect to nouns), it has nevertheless prevailed in most languages. Even in English you can sometimes find nouns with a starting capital letter. That applies not only to the spoken language, but also to programming languages or naming conventions for programming. For example, the CamelCase notation states that in compound words, the first letters of each word are capitalized.
CamelCase
You can also find a trend where the first word of a compound word starts with a small letter:
camelCase
With that, the use of capital letters is also a commonly used convention for marking words, identifiers, function names, etc. in compound expressions.
The definition of rules for the notation of identifiers, function names, etc. is widely accepted among programmers and ultimately leads to a naming convention that determines how the language elements of a programming language are to be written. Still, many developers find it challenging to adhere to naming conventions. In fact, it can often be observed that developers are not consistent with their “own” preferred convention.
Compliance with naming conventions increases the readability of text in general and in programming. The same sentence again with deviations from generally known naming conventions that nouns are capitalized and adjectives, as well as verbs are written in small letters, the text becomes quickly illegible: “Compliance WITH nAming conventions INCREASES the Readability of text in general and in programming in Particular.”
The following statement is defined in the view vTimeSeries in the database AdventureWorksDW2017 and was slightly revised by me. I did not bother to follow any naming convention.

In the following statement, function names are capitalized, all field names are delimited by square brackets, data types are written in lower case letters, and finally the statement is consistently aligned and formatted …

Whether or not the applied formatting is preferred by the reader, we probably can agree on that the second statement appears to be more readable.
With that there are some points identified being an essential part in a naming convention. In addition, there are a few other things to be discussed:
- Regular Identifier
- Delimiter
- The Spacer
- The Semicolon
- The Comma
- Funktion Names
- Aliases
- Qualified Field Names
Regular Identifier
Of course, all database objects have a name, the so-called identifier. Each database provider specifies rules for assigning a valid identifier. For example, in SQL Server, the length of identifiers is typically limited to 128 characters, and a regular identifier must not contain spaces. The exact definition of a regular identifier can be found in the online documentation:
However, the definition of a regular identifier is, in my opinion, a much too broad definition.
While – for example – the underscore _ is widely used as a separating character between words, I usually avoid this character because the notation of a CamelCase identifier serves the same purpose and makes identifiers more compact.
Special characters like the @, #und $ are supported in regular identifiers. The use of these characters – in my opinion – makes an identifier illegible. These characters are too similar to letters from the Latin alphabet and yet cannot be directly grasped as such. That is why I usually try to avoid these characters.

I use only letters of the Latin alphabet [a-zA-Z] for identifiers. As long as it is possible, I try to avoid using numbers [0-9], too. This reduces the number of rules for choosing a good identifier to only two rules:
- Use letters of the Latin alphabet
- If ever possible avoid numbers
Delimiters
Once an identifier contains a space, the identifier is no longer a regular identifier. However, non-regular identifiers are allowed if the identifiers are enclosed by either quotation marks (“”) or square brackets ([]). The use of non-regular identifiers is not a good programming style.
The use of quotation marks is standard in most SQL dialects. Microsoft also allows square brackets here. Since delimiters differentiate identifiers visually from other elements of an SQL statement, delimiters contribute significantly to the readability of an SQL statement. I always use delimiters and I prefer square brackets over quotation marks.
Among others I use delimiters for the following elements of the SQL vocabulary:
- Schemas
- Tables
- Views
- Field Names
- Aliases
- All programmable objects (Stored Functions, Stored Procedures, etc.)
The following statement corresponds exactly to the second statement from this article. However, the identifiers are not noted with delimiters. Decide on your own which notation appears to be more readable:

Obviously, Microsoft prefers the use of square brackets over quotation marks. Many automatically created scripts are created by using square brackets as delimiters. SQL Server Management Studio (SSMS) uses – for example – square brackets for automatically generated SELECT and DDL statements (via the context menu for a table). Unfortunately, Microsoft is not very consistent here. When creating views via the wizard or showing the SQL statement in the SQL panel of the edit feature, Microsoft does not use delimiters, if delimiters are regular delimiters. The following two screenshots show automatically generated SQL statements. These statements can be regarded as a good example for how statements shall not be formatted with respect to the readability.
View
Edit Feature

Using delimiter is only supported with SET QUOTED_IDENTIFIER ON. With QUOTED_IDENTIFIER OFF regular identifiers are no supported in SQL Server:
The Spacer
The natural reading order (of an SQL statement) is left to right and top to bottom.
While software code consists of quite a few short statements, SQL is designed to perform many operations in a single statement. A SQL statement can quickly cover hundred or more lines. With that, writing a good SQL statement appears to be challenging. An essential criterion for the understanding of an SQL statement is not only a clear structure and formatting of the statement, but also whether the statement is compact enough to get the major task on a short glance at the statement.
When using a high resolution and common editor font settings a maximum of 40 lines of SQL code are visible on a common monitor in SSMS. Most developers, however, will have only 25 lines code on the screen.
There are developers that insert blank lines after each line of code. An excessive use of blank lines requires the reader of a statement to use navigation keys or the mouse wheel to be able to read the complete statement.
Blank lines can be a good stylistic means of separating logical blocks. Excessive use, however, makes a statement harder to read.
The Semicolon
According to standard SQL all SQL statements must be terminated with a semicolon. At least SQL Server does not force the programmer to use the semicolon.
There are only a few cases where the use of a semicolon is mandatory. For example, when using a Common Table Expression (starting with the keyword WITH), the preceding statement must be terminated with a semicolon.
In any case, using the semicolon is not only a matter of improving the readability of an SQL statement. It may help migrating an existing database application to a database of another provider.
And finally, using semicolons proves the developer to be accurate.
The Comma
In an SQL statement a list of field names must be separated by a comma. When writing field names with each other you can prefix or suffix the field names with a comma. The pros and cons usually concentrate on the philosophic question how difficult it is to add a new field to the field list.
The most important reasons for prefixing field names are an improved readability on the one hand and a possible usage of the column editor feature on the other hand (see also Functional Design (Aesthetics) of SQL).
Prefixing field names

Let’s assume that we want to add the field name FrenchDayNameOfWeek to the list of field names. Obviously, it appears to be easier to add the field at the end of the list. You just insert the following line
,[FrenchDayNameOfWeek]
behind the field SpanishDayNameOfWeek:

In opposite, when inserting the field at position one – before the field EnglishDayNameOfWeek – two modifications are required: Add the field name
[FrenchDayNameOfWeek]
at position one without a trailing comma and prefix the second field with a comma.

Suffixing field names
When suffixing field names, the above arguments turn into the opposite: it is easier to add a new field at the beginning of a field list.
Readability
The comma is a separator. It marks the change from one field to the next. If the comma is written behind a field name, it loses its separating character due to the different lengths of the field names.
In the following statement it is not immediately clear whether the identifier Alias is a field name or has a different meaning. The reader must read the line above the identifier Alias in order to determine that the identifier is to be read as an alias.

It is different with the comma written before field names. In this case, it is immediately obvious that the identifier Alias is not a field name because it has no preceding comma:

The comma and the column editor feature
Have a look at the following statement. It appears to be quite challenging to add aliases to all field names.

Each comma must be moved to the right. Before the comma you must add the keyword AS and after the keyword AS you must enter the aliases. These actions must be done line by line. What an effort for adding 5 aliases.

You can minimize the effort involved by prefixing the field names with commas and aligning neatly. In that case you can take advantage of the column editor feature.
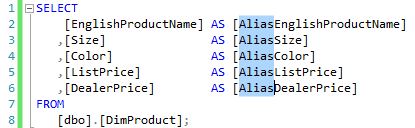
There are no commas to move. The column editor allows you to type the keyword AS only once, the field names can be used as the base for the aliases. Copy the field names behind the keyword and use the column editor to prefix the aliases with the text Alias. And the best of all: The effort for this is largely independent of the number of lines to be processed.
Function Names
Function names are highlighted by pink letters in SSMS, making them easy to identify. Since not all editors use color highlighting of function names, function names should also be identified by a uniform notation: Function names should be written either only in capital letters or only in small letters.
Microsoft itself – but also other database providers – note function names in capital letters in the online documentation. So, why deviate from the standard?
Table Aliases
A common practice is to derive meaningful table aliases from the table name. For example, by writing the starting letters of the compound words of the table name. With that rule you can find for the table FactInternetSales the alias IS. The letters result from the first letters of the word components of the table name ignoring the prefix Fact. Since IS is a reserved word, this alias must be wrapped with delimiters. For other tables, the following aliases could be derived:
| DimCustomer | CUST |
| DimProduct | P |
| DimProductCategory | PC |
| DimProductSubcategory | PSC |
A SELECT Statement using the above tables would look like as follows:

The varying indentation of the field names results from different lengths of the aliases. These have a length between 1 and 4 characters. The field list appears restless and can quickly become illegible with more complex statements and the use of other language elements (functions, CASE statements, etc.).
Imagine a SELECT statement based on 20 or more tables. At some point it will be difficult finding meaningful aliases for table names. Aliases may then appear too cryptic.
My personal view on meaningful aliases is that these aliases do not really improve the readability of a statement.
Wouldn’t it be easier to identify systematic – perhaps even indexed aliases – in a complex statement?
Systematic aliases could be defined as follows:
- The length of aliases is being limited to a fixed number of characters
- Aliases names are indexed
For example, using the letter T for tables as an alias (or F for fact table, D for dimension, etc.) followed by a 2-digit 1-based index with trailing zeroes, aliases would result to T01, T02, D01, F01, etc.
Using those aliases, the above statement appears more readable:

The field names within the SELECT list are neatly aligned.
However, the actual killer argument is also here: the notation of fixed length aliases allows the use of the power feature column editor.
In addition to this argument, there is another important reason why to use aliases: Only by using aliases, the Intellisense feature can be used efficiently. If the developer writes an alias followed by a dot, then a context menu opens showing only the field names associated with the alias:
The context menu can – if the cursor is behind the dot – also be open manually by using the shortcut CTRL+space. Of course, the context menu can also be used without the context of the preceding alias. However, SSMS then offers the entire vocabulary of T-SQL in the context menu.

Aliases make SQL code more readable and thus maintainable. Therefore, using aliases should be mandatory.
Qualified Field Names
If a statement covers multiple tables, you will be facing a situation where the same field name is available in more than one table. The following statement wants to return the names and phone numbers of both the employee and the reseller:

The statement is not executable because the field Phone exists in both dimensions DimEmployee and DimReseller. SQL Server throws two ambiguous column exceptions. Specifying an alias is mandatory here.

When defining an alias, then the developer must qualify a field name with that alias.
T01.[Phone] AS [Employee_Phone]
Using aliases means, that you use qualified names for an object. Another example for a qualified field name is prefixing the field name with the table name:
[DimEmployee].[Phone] AS [Employee_Phone]
.
This option, however, does not really improve the readability of a statement.
A fully qualified field name consists of 5 parts:
[Server].[Database].[Schema].[Table].[Column]
n example for almost fully qualified object names you will find in the following statement:

Qualifying an object beyond the schema name prevents a database application from being deployable in a database with a different name.
After all, using aliases should be mandatory at all, but be aware of the portability of a database application. Do not qualify object names beyond the schema unless there is a good reason for this.