Ein einziger nicht konvertierbarer Datums-Text, und der ganze ETL-Lauf bricht ab. Das hier vorgestellte Design Pattern für die Architektur eines ETL-Prozesses verhindert genau das: schlechte Daten werden isoliert, nicht weitergereicht.
TL;DR — was dieser Artikel zeigt:
- Arbeitspakete und Schema-Schichtung E0 – L2 — wie sich der ETL-Prozess in trennscharfe, in sich geschlossene Pakete mit jeweils eigenem Datenbankschema zerlegen lässt.
- Technische vs. strukturelle Transformation — warum Typisierung und Fremdschlüssel-Auflösung als getrennte Pässe sicherer und besser debugbar sind als in einem.
- Datenqualität an den Schema-Grenzen — fehlerhafte Datensätze werden an den Übergängen abgefangen, der Hauptstrom läuft sauber weiter.
- Historisierung als optionale Schicht — SCD 1 / SCD 2 spielen ihren Wert vor allem bei Delta-Loads aus.
Voraussetzung. Grundverständnis von ETL-Prozessen. Konzeptueller Artikel — kein Schritt-für-Schritt-Tutorial. Wurzel der Artikelserie: Datenqualität in einem ETL-Prozess; der vorliegende Artikel ist der Architektur-Teil.
Inhalt
Aufgaben des ETL-Prozesses
Ein Prozess besteht aus den drei allgemeinen Schritte E = Extract, T = Transform und L = Load. Was aber genau in diesen übergeordneten Arbeitsschritten durchzuführen ist, bleibt Definitionssache.
Extraktion
In diesem Schritt werden Daten aus verschiedenen Datenquellen extrahiert. Das können Datenbanken sein, Dateien oder auch APIs. Die zu extrahierenden Daten können strukturiert oder unstrukturiert sein und in verschiedenen Formaten vorliegen. In dieser Artikelserie werden ausschließlich strukturierte Daten behandelt. Strukturierte Datenquellen sind relationale Datenbanksysteme, aber auch CSV-Dokumente sowie XML- und JSON-Dokumente, sofern ihre Datenelemente einer logischen Struktur folgen. Unstrukturierte Daten wie zum Beispiel Texte aus sozialen Netzwerken werden hier nicht berücksichtigt.
Bei dieser allgemeinen Definition der Extraktion bleibt jedoch unklar, was genau mit Extraktion gemeint ist. Eine konkrete Ausgestaltung des Extraktionsprozesses wird in den folgenden Abschnitten beschrieben:
- Materialisierung der extrahierten Daten
- Erweiterte Aufgaben der Extraktion
- Keine Typisierung der Daten
Materialisierung der extrahierten Daten
Das hier vorgestellte Design Pattern speichert alle extrahierten Daten in einer Datenbank. Die Daten sind so zu speichern, dass bei diesem Schritt kein technischer Grund vorliegen darf, dass die Daten nicht in der Datenbank gespeichert werden können. Einziger zulässiger Grund für einen Abbruch bei der Extraktion sind Probleme mit der Infrastruktur (Speicherplatz, Netzwerk, etc.). Die Speicherung von Daten in einer Datenbank bezeichne ich hier als Materialisierung der Daten.
Die Extraktion und Materialisierung der extrahierten Daten haben vor allem drei Vorteile:
- Minimierung der Zugriffsdauer auf die Daten des Quellsystems
- Verfügbarkeit aller extrahierten Daten in einer Datenbank
- Möglichkeit der nachträglichen Fehleranalyse
Der Zugriff auf Datenbanken des Quellsystems kann das Quellsystem so weit belasten, dass die Performance und Reaktionszeiten des Quellsystems in Mitleidenschaft gezogen werden. Durch eine Extraktion wird die Dauer des Zugriffs minimiert.
Liegen alle extrahierten Daten in einer Datenbank vor, können die extrahierten Daten über SQL weiterverarbeitet werden. Für die Weiterverarbeitung ist insbesondere kein ETL-Tool erforderlich, das Daten aus unterschiedlichen Systemen integriert. Hierdurch werden unter anderem technische Hürden reduziert und im Zweifel sind nachfolgende Prozesse hinsichtlich Ausführung und Entwicklung wesentlich performanter.
Erweiterte Aufgaben der Extraktion
Bei Textdateien im Format XML und JSON (und ggf. auch CSV) verhält es sich bei der Materialisierung ein wenig anders. XML– und JSON-Dokumente werden vor der Extraktion der darin enthaltenen Daten in der Datenbank gespeichert. Als erweiterte Aufgabe der Extraktion sind die Attribute aus den Dokumenten über mächtige T-SQL-Funktionen wie zum Beispiel OPENXML oder OPENJSON zu extrahieren und in der Datenbank zu speichern.
Keine Typisierung der Daten
Insbesondere Datenlieferungen über Text-Dateien sind problematisch. Die enthaltenen Daten liegen keineswegs typsicher vor. Ein Datum, das als Text geliefert wird, kann gegebenenfalls nicht in einen Wert vom Typ date konvertiert werden. Zwischen dem die Daten liefernden Prozess und dem ETL-Prozess muss es eine Vereinbarung darüber geben, in welchem Format zum Beispiel ein Datum geliefert wird (yyyy/dd/MM, dd.MM.yyyy, etc.). Die Konvertierung von Werten im Zuge der Extraktion ist eine Fehlerquelle und birgt die Gefahr des Abbruchs des ETL-Prozesses. Die Konvertierung von Daten in die Zieldatentypen ist im Rahmen der Extraktion daher nicht zulässig.
Transformation
Eine gängige Definition des Schrittes der Transformation könnte so lauten: Die Transformation hat zum Ziel, die extrahierten Daten in das gewünschte Format zu bringen. Eine andere mögliche Definition subsummiert die erforderlichen Aufgaben auch gerne unter dem Begriff der Datenintegration. Beide Definitionen und der Begriff Datenintegration sind alles und nichts sagend und geben keinen Hinweis auf die erforderlichen bzw. konkreten Maßnahmen.
Ausgehend von den extrahierten Daten fallen – gemäß des hier vorgestellten Design Patterns – grundsätzlich zwei verpflichtende und eine optionale Aufgabe an:
- Typisierung der extrahierten Daten
- Prüfung der Datenqualität
- Optional: Historisierung
Werden die Daten in Textdateien geliefert, dann sind die extrahierten Attribute zunächst in die Zieldatentypen zu konvertieren. Dieses gilt übrigens auch oft für den Fall, wenn Daten aus Datenbanken extrahiert werden und die Datentypen des Quell- und des Zielsystems auseinanderlaufen. Beschränken wir uns hier aber auf Textdateien als Datenquelle. Wie oben beschrieben, werden aus Textdateien extrahierte Werte zunächst als Werte vom Typ Text gespeichert. Das Zielsystem erwartet aber stark typisierte Daten. So wird zum Beispiel ein Datum regelmäßig in einen Wert vom Typ date zu konvertieren sein.
Die Prüfung der Datenqualität ist zudem eine äußerst wichtige Aufgabe, die einen fundamentalen Einfluss auf das Ergebnis eines ETL-Prozesses hat. Sie beginnt hier mit der Prüfung, ob ein gelieferter Wert in den Datentyp des entsprechenden Zielfeldes in dem Zielsystem konvertiert werden kann. Gegebenenfalls müssen die gelieferten Daten auf Duplikate geprüft werden. Es gibt noch zahlreiche andere sinnvolle und notwendige Prüfungen sowie Aufgaben, die im Rahmen der Prüfung der Datenqualität durchzuführen sind.
Im Zuge der Historisierung werden die als geändert identifizierten Quelldaten (neue, geänderte oder gelöschte Daten) in separaten Tabellen fortgeschrieben, so dass immer nachvollziehbar ist, wann ein Datensatz eingefügt, geändert oder gelöscht wurde. Dieser Schritt ist optional. Ein Kollege hat die historisierten Daten mal Gehirn des ETL-Prozesses bezeichnet. Die Daten des nachfolgenden Zielsystems können so jederzeit aus den historisierten Daten wiederhergestellt werden. Natürlich erfordert die Historisierung weitergehende Wartungsaufgaben, wie zum Beispiel Sicherungsaufgaben.
Der Begriff Datenintegration bezeichnet am ehesten die strukturelle Transformation. Es werden Daten aus verschiedenen Datenquellen gefiltert, zusammengeführt und aggregiert. Obwohl es sich auch hier um eine Transformationsaufgabe handelt, wird diese Aufgabe – gemäß des hier vorgestellten Design Patterns nicht im Rahmen des T des ETL-Prozesses durchgeführt, sondern im Rahmen des L des ETL-Prozesses. An dieser Stelle angelangt ist es hilfreich, die in diesem Abschnitt beschriebenen Transformationsaufgaben von der strukturellen Transformation begrifflich scharf zu trennen. Die Transformationsaufgaben, die in diesem Abschnitt beschrieben und im Rahmen des T des ETL-Prozesses durchzuführen sind, werden daher als technische Transformation bezeichnet. Die Transformationsaufgaben, die in dem L des ETL-Prozesses durchzuführen sind, werden als strukturelle Transformation bezeichnet.
Die Grenzen für die Zuordnung einer Aufgabe zu einem der übergeordneten Schritte eines ETL-Prozesses fließend und am Ende eine Frage der Definition.
Typisierung der extrahierten Daten
Sofern die Datenquelle eine Datenbank wie zum Beispiel SQL Server oder Oracle ist, sollten Daten üblicherweise streng typisiert vorliegen. Trotzdem die Daten einer Quelldatenbank in der Regel stark typisiert sind, kann auch hier eine Typisierung entsprechend des Datentyps in dem Zielsystem erforderlich sein.
Beispiel. Als Beispiel kann die Länge von Textfeldern genannt oder die Speicherung eines Datums ohne Angabe der Zeitzone genannt werden. Softwareentwickler legen bisweilen keinen starken Fokus auf die Begrenzung der Eingabe von Texten. Damit kann es vorkommen, dass zum Beispiel in einem Adressfeld in dem Quellsystem ganze Romane gespeichert werden können. Anwender, die solch eine Lücke bei der Nutzung einer Anwendung entdecken, werden diese – erfahrungsgemäß – auch nutzen, um dort weitere Informationen einzugeben, die dort einfach nicht hingehören. Unterstützt das Quellsystem keine Speicherung eines Datums mit Zeitzone, so ist die Zeitzone des Quellsystems zu ermitteln und bei der Konvertierung in den Zieldatentyp Datum plus Zeitzone zu berücksichtigen.
Bei der Verarbeitung von extrahierten Attributen, die aus einer Textdatei gelesen werden, ist immer eine Typisierung der extrahierten Werte in die Zieldatentypen erforderlich.
Beispiel. Im Zuge der Extraktion werden die extrahierten Attribute als Werte vom Typ Text gespeichert. Ein Text, den wir augenscheinlich als Datum interpretieren, muss nicht zwangsläufig in einen Wert vom Typ Datum konvertierbar sein. So ist der Text 30-02-2023 kein gültiges Datum. Ein weiteres Beispiel: Der Text 03-05-2023 kann nicht ohne zusätzliche Information über die Datenquelle als Datum interpretiert werden. Die Interpretation nach amerikanischer Schreibweise gemäß der Formatzeichenfolge mm-dd-yyyy ergibt als Datum den 05.03.2023, während die Interpretation gemäß Deutscher Schreibweise und der hiesigen üblichen Formatzeichenfolge dd-mm-yyyy das Datum 03.05.2023 ergibt. Für die korrekte Interpretation ist die Kenntnis über das Datums-Format – also die Formatzeichenfolge – erforderlich. Ähnliche Aufgaben und Herausforderungen gibt es bei Zahlen mit Bezug zu dem Dezimal- und Tausendertrennzeichen.
Prüfung der Datenqualität
Bei der Prüfung der Datenqualität werden die extrahierten und konvertierten Daten auf Vollständigkeit und Korrektheit geprüft. Diese Prüfungen umfassen ein weites Feld. Beispiele hierfür sind:
- Prüfung der Typisierung
- Identifikation von Duplikaten
- Prüfung der Schreibweise und Rechtschreibung von Texten
- Prüfung von Fremdschlüsseln
- Prüfung fehlender Werte für Pflichtfelder
- Validierung von Geschäftslogiken
In dem Artikel Datenqualität in einem ETL-Prozess wurde der Begriff der technischen Datenqualität vorgestellt. Die Prüfung der technischen Datenqualität erfolgt auf den typisierten Daten. Für die Prüfung der Datenqualität in den typisierten Daten können einfach logische Bedingungen aufgestellt werden, über die Fehler in einem Wert bzw. einem Datensatz identifiziert werden. Eine logische Bedingung wird technisch als WHERE-Klausel in dem ETL-Prozess hinterlegt und auf die typisierten Daten angewendet. Liefert eine WHERE-Klausel Datensätze zurück, enthalten diese in dem untersuchten Feld, auf das sich die WHERE-Klausel bezieht, einen Fehler.
Prüfung der Typisierung
Der Erfolg oder Misserfolg der Typisierung hat unmittelbaren Einfluss auf alle nachfolgenden Aufgaben. Kann ein Eingangswert nicht in den Zieldatentyp konvertiert werden, darf Datensatz, der den Fehler enthält, gegebenenfalls nicht weiterverarbeitet werden. Über das hier vorgestellte Design Pattern wird für alle gelieferten Quelldaten geprüft, ob Eingangswerte in den jeweiligen Zieldatentyp konvertiert werden können.
Identifikation von Duplikaten
Die Identifikation von Duplikaten kann beliebig komplex sein. In dieser Artikelserie beschränke ich mich auf eine Kombination von Feldern, die in der Datenlieferung einer vorgegebenen Kardinalität entsprechen oder eindeutig sein muss (Kardinalität = 1).
Prüfung der Schreibweise und Rechtschreibung von Texten
Für Telefonnummern gibt es zahlreiche Schreibweisen. Nach der DIN-Norm 5008 ist die Vorwahl ohne Klammern zu schreiben und von der restlichen Telefonnummer durch ein Leerzeichen zu trennen. Prüfung auf korrekte Schreibweise eines Wertes kann im Rahmen der technischen Transformation durchgeführt werden.
Prüfung von Fremdschlüsseln
Enthalten die gelieferten Daten eine Fremdschlüssel-Beziehung, ist hier nur die strukturelle Gültigkeit eines gelieferten Fremdschlüssel-Werts zu prüfen — also Format, Pflicht-Vorhandensein und Datentyp. Die eigentliche Ermittlung des Fremdschlüssels gegen das Zielsystem (Mapping Source-Code → Target-Surrogate) erfolgt erst später, im Rahmen der strukturellen Transformation. Der Grund für die Trennung: die Ermittlung braucht Kontext aus dem Zielsystem (etwa eine Länder-Tabelle), die Format- und Pflicht-Prüfung kommt mit dem Datensatz allein aus.
Prüfung fehlender Werte für Pflichtfelder
Ist ein Attribut in dem Zielsystem ein Pflichtfeld, für das ein Wert vorliegen muss, so sind die typisierten Daten daraufhin zu prüfen, ob hier ein entsprechender Wert geliefert wird.
Validierung von Geschäftslogiken
Die Prüfung von Geschäftslogiken ist ein weites Feld und kann beliebig komplex sein. Aber bereits durch die Prüfung einfacher Geschäftslogiken, kann die Datenqualität im Zweifel erheblich verbessert werden. Als Beispiel für eine einfache Geschäftslogik könnte zum Beispiel das Geburtsdatum eines Kunden sein. Das Geburtsdatum darf selbstredend nicht in der Zukunft liegen.
Laden
Typisierte Daten werden im letzten Schritt des ETL-Prozesses strukturell entsprechend den Datenstrukturen des Zielsystems transformiert, gegebenenfalls noch mal auf Datenfehler hin untersucht, gefiltert und aggregiert, historisiert und schließlich in das Zielsystem geladen. Es sind die folgenden Aufgaben durchzuführen:
- Strukturelle Transformation
- Prüfung der Datenqualität
- Filterung
- Aggregation
- Optional: Historisierung
- Laden der Daten in das Zielsystem
Die zuvor technisch transformierten Daten können in verschiedene Zielsysteme geladen werden. Das Zielsystem, kann ein CRM-System sein, aber natürlich auch ein Datawarehouse. Die Aufgabe der strukturellen Transformation ist spezifisch für ein bestimmtes Zielsystem. Daher erfolgt die strukturelle Transformation im Rahmen des L aus dem ETL-Prozess. Auch hier gilt wieder: Die Grenze zwischen den übergeordneten Schritten eines ETL-Prozesses sind fließend und es ist eine Frage Definition in welchem Schritt des ETL-Prozesses, welche Aufgaben durchgeführt werden.
Strukturelle Transformation
Die strukturelle Transformation erfolgt ausschließlich auf der Basis der typisierten, qualitätsgesicherten und gegebenenfalls historisierten Daten, die als fehlerfrei erkannt wurden. Technisch betrachtet entspricht die strukturelle Transformation einem SELECT-Statement, das die Daten aus den historisierten Tabellen über JOINs verknüpft und entsprechend den Strukturen der Daten in dem Zielsystem aufbereitet. Im Rahmen der strukturellen Transformation sind unter anderem Fremdschlüssel zu ermitteln sowie Lookup-Werte aufzulösen:
- Ermittlung von Fremdschlüsseln
- Auflösung von Lookup-Werten
Das Ergebnis der strukturellen Transformation wird – wie schon bei der Extraktion und der technischen Transformation – in einer Datenbank materialisiert, um auch diese Daten für eine Analyse und Fehlersuche verfügbar zu machen. Die Datenstrukturen der strukturell transformierten Daten entsprechen weitestgehend den Datenstrukturen der Daten in dem Zielsystem. Insbesondere werden im Zuge der strukturellen Transformation die Spaltennamen und Datentypen des Arbeitsergebnisses so gewählt, wie sie durch das Zielsystem vorgegeben sind.
Ermittlung von Fremdschlüsseln
Können Fremdschlüssel nicht auf der Basis der extrahierten Daten ermittelt werden, sind Fremdschlüssel gegen die Daten des Zielsystems zu ermitteln.
Beispiel. So werden Länder in dem Zielsystem regelmäßig in einer separaten Tabelle gespeichert. Das Land United States in dem Zielsystem wird hier sowohl durch die Länderbezeichnung aber auch – normalerweise – einen technischen Schlüssel (z.B. eine GUID) identifiziert. Bei der strukturellen Transformation eines Kunden ist das Land des Kunden, das in der Quelle durch den Text United States angegeben ist, in den Primärschlüssel des Landes United States des Zielsystems zu übersetzen und als Fremdschlüssel auf das Land United States mit dem Kunden zu speichern.
Die Ermittlung des Fremdschlüssels erfordert entweder einen direkten lesenden Zugriff auf die Tabelle Länder des Zielsystems oder – wenn kein direkter Zugriff besteht – diese ist vor der strukturellen Transformation zu lesen und die Daten sind in einer Datenbank verfügbar zu machen. An diesem Punkt angelangt, handelt es sich bei dem Lesen der Tabelle Länder wiederum um eine Extraktionsaufgabe.
Auflösung von Lookup-Werten
Häufig verwenden Quell- und Zielsysteme unterschiedliche Werte für die Speicherung eines Wertes eines Auswahlfeldes. Ein Auswahlfeld ist zum Beispiel ein Listenfeld, über das die Anrede eines Kunden ausgewählt werden kann.
In einer Datenbank wird selten die in der Anwendung angezeigte und ausgewählte Anrede gespeichert. Gespeichert wird möglicherweise der Wert 1 für die Anrede Herr und der Wert 2 für die Anrede Frau. Die Kodierung der Anrede in dem Quellsystem und dem Zielsystem weicht normalerweise voneinander ab.
Die Kodierung solcher Attribute ist häufig nicht in separaten Tabellen gespeichert. Die Übersetzung des Codes des Quellsystems in den Code des Zielsystems erfordert somit das Wissen um die Regeln für die Übersetzung des Codes. Die Übersetzung des Codes des Quellsystems in den Code des Zielsystem wird in Anlehnung an Begrifflichkeiten von Microsoft CRM Dynamics als Auflösung von Lookup-Werten bezeichnet. Für die Auflösung von Lookup-Werten, sind die Codes des Quell- und des Zielsystems zu ermitteln und in einer Mapping-Tabelle zu speichern, die bei der strukturellen Transformation abgefragt wird.
Prüfung der Datenqualität
Die Erfahrung aus dem Projektgeschäft hat gezeigt, dass die Ermittlung von Fremdschlüsseln sowie die Auflösung von Lookup-Werten eine große Fehlerquelle darstellt, die in einer unvollständigen oder fehlerhaften Ermittlung des Mappings der Codes des Quellsystem auf die Codes des Zielsystems begründet ist.
Filterung
Sofern es sich bei dem Zielsystem nicht um eine initiale Befüllung mit Daten handelt, sind nur Daten mit bestimmten Eigenschaften in das Zielsystem zu laden. Die Filterung auf tatsächlich zu ladende Daten kann – sofern möglich – bereits bei der technischen Transformation erfolgen. Ist dieses dort nicht möglich, sind die Daten im Zuge der strukturellen Transformation zu filtern.
Datenaggregation
Gegebenenfalls sind Daten vor dem Laden des Zielsystems zu aggregieren.
Wenn eine durchgängige Nachvollziehbarkeit aller Prozessschritte in einem ETL-Prozess gewährleistet sein soll, ist zu überlegen, ob der Aggregationsprozess auf den Daten der strukturellen Transformation nachgelagert als zusätzlicher Prozessschritt vorzunehmen ist. Aggregierte Daten wären in diesem Fall in separaten Tabellen einer Datenbank zu speichern.
Historisierung
Wie schon bei der technischen Transformation können die strukturell transformierten und geprüften Daten in separaten Tabellen fortzuschreiben. Neue Daten werden hier eingefügt, geänderte Datensätze werden hier aktualisiert und gelöschte Datensätze als gelöscht markiert.
Laden der Daten in das Zielsystem
Das abschließende Laden der geänderten Daten in das Zielsystem erfolgt somit auf qualitätsgesicherten strukturell transformierten und historisierten Daten. Es werden nur fehlerfreie Datensätze, bei denen also Fremdschlüssel und Lookup-Wert erfolgreich ermittelt werden konnten, in das Zielsystem geladen.
Technologisch beschränkt sich dieses Buch auf das Laden der Änderungsdaten in eine Ziel-Datenbank. Die Aktualisierung in dieser Ziel-Datenbank erfolgt über SQL-Statements, also über INSERT-, UPDATE- und gegebenenfalls auch DELETE-Statements. Andere Zielsysteme – wie zum Beispiel Dynamics 365 von Microsoft – erfordern die Nutzung einer proprietären API, um Daten in das Zielsystem schreiben oder auch um Daten von dort lesen zu können. In diesem Fall ist es erforderlich, ein ETL-Tool wie zum Beispiel SQL Server Integration Services, zu nutzen.
Architektur des ETL-Prozesses
Die hier vorgestellte Architektur eines ETL-Prozesses ist allgemeingültig und kann unabhängig von der Art der zu extrahierenden Datenquellen und der Zielsysteme in Datenmigrations- und Datenintegrationsprojekten eingesetzt werden. Sie eignet sich ebenso für die Datenbewirtschaftung eines Datawarehouse. Der ETL-Prozess wird in kleine in sich geschlossene Arbeitspakete heruntergebrochen. Die durchzuführenden Aufgaben der Arbeitspakete sind trennscharf definiert. Im Zuge der Datenverarbeitung wird die Datenqualität geprüft. Nach Abschluss der Arbeit in einem Arbeitspaket werden nur fehlerfreie Daten an das jeweils folgende Arbeitspaket weitergereicht. Am Ende des Prozesses stehen qualitätsgesicherte Daten in Datenstrukturen zur Verfügung, die ähnlich zu den Strukturen in dem Zielsystem sind und ohne weitere Transformationsaufgaben direkt dorthin geladen werden können.
Arbeitspakete des ETL-Prozesses
Das folgende Schaubild veranschaulicht die Arbeitspakete des hier vorgestellten ETL-Prozesses:

In der Abbildung werden in der oberen Zeile zunächst die übergeordneten Schritte analog zu dem Akronym ETL dargestellt: Extract, Transform und Load. Die untere Zeile benennt die konkreten Arbeitspakete des ETL-Prozesses und ordnet diese einem übergeordneten Schritt zu. Jedem Arbeitspaket ist ein Datenbankschema zugeordnet. In der Mitte werden die von dem ETL-Prozesse verwendeten Schemas je Arbeitspaket benannt (E0–L2). Im Zuge der Datenverarbeitung werden die Daten von Arbeitspaket zu Arbeitspaket bzw. Schema zu Schema weitergereicht. Der ETL-Prozess besteht aus den folgenden Arbeitspaketen:
- Extraktion der Daten
- Technische Transformation
- Historisierung der technisch transformierten Daten
- Strukturelle Transformation
- Historisierung der strukturell transformierten Daten
- Laden der Daten in das Zielsystem
Die Arbeitspakete Technische Transformation und Strukturelle Transformation prüfen die Datenqualität der transformierten Daten und reichen nur fehlerfreie Daten an das folgende Arbeitspaket weiter. Die Prüfung der Daten ist in der Abbildung durch die dunklen Pfeil-Spitzen dargestellt. Die nachfolgenden Abschnitte fassen die Arbeitsschritte der einzelnen Arbeitspakete zusammen und geben einen Überblick über die zu verwendende Technologie, mit der die Arbeitsschritte in den Arbeitspaketen durchgeführt werden.
Extraktion
Ziel der Extraktion ist, alle zu verarbeitenden Daten zunächst in der Schnittstellendatenbank zu speichern. Bei der Extraktion ist zu unterscheiden, ob die zu extrahierenden Daten aus einer Datenbank oder Dokumenten mit tabellenähnlichen Strukturen – wie zum Beispiel EXCEL- oder CSV-Dokumente – gelesen werden, oder ob Dokumente mit komplexen logischen Strukturen – wie zum Beispiel XML oder JSON – zu verarbeiten sind.
Extraktion aus einer Datenbank

Detail-Schaubild Extraktion aus einer Datenbank: aktiver ETL-Schritt Extract, die Quelle Database wird in Schema E1 materialisiert.
Werden Daten aus einer Datenbank oder tabellenähnlichen Strukturen gelesen, werden die Attribute/Spalten zunächst in Tabellen des Schemas E1 materialisiert. Die Strukturen der Tabellen in dem Schema E1 entsprechen weitestgehend den Strukturen in dem Quellsystem. Sind Daten aus einer Datenbank zu extrahieren, werden die Daten mit den Datentypen gespeichert, in denen sie in dem Quellesystem abgelegt sind. Werden die Datentypen des Quellsystems nicht durch SQL Server unterstützt, sind die Daten der Datenquelle in den Tabellen des Schemas E1 mit dem Datentyp nvarchar zu speichern.
Extraktion aus Dokumenten mit tabellenähnlichen Strukturen

Daten aus Dokumenten mit tabellenähnlichen Strukturen, wie zum Beispiel EXCEL- und CSV-Dokumente, können nicht typsicher geliefert werden. Häufig werden diese Dokumente manuell erstellt und gepflegt und der ETL-Prozess kann sich nicht darauf verlassen, dass in einer Spalte zum Beispiel ein gültiges Datum geliefert wird. Um sicherzustellen, dass alle Daten aus diesen Dokumenten in der Schnittstellendatenbank in den Tabellen des Schemas E1 materialisiert werden können, sind alle Daten zunächst mit dem Datentyp nvarchar zu speichern. Für die Speicherung in diesen Tabellen sind maximale Textlängen zu verwenden, um sicher zu stellen, dass die Daten dort materialisiert werden können.
Extraktion aus Dokumenten mit komplexen logischen Strukturen

Sind XML-/JSON-Dokumente zu verarbeiten, werden diese zunächst selbst in Tabellen des Schemas E0 gespeichert. Die Extraktion der Attribute erfolgt in Tabellen des Schemas E1. Hierbei werden die Dokumente verarbeitet, die im ersten Arbeitsschritt in den Tabellen des Schemas E0 gespeichert wurden.
Attribute aus Text-Dateien werden in den Tabellen des Schemas E1 als Werte vom Typ nvarchar gespeichert. Für die Speicherung in diesen Tabellen sind maximale Textlängen zu verwenden, um sicher zu stellen, dass die Daten dort gespeichert werden können.
Technologie
Die Extraktion von Daten aus einer Datenbank oder tabellenähnlichen Strukturen kann mit SQL Server Integration Services (SSIS) von Microsoft oder auch jedem anderen ETL-Tool durchgeführt werden. Sind XML- oder JSON-Dokumente zu extrahieren, werden diese Dokumente ebenfalls mit SSIS zunächst in die Tabellen des Schemas E0 geladen. Die Extraktion der Attribute aus den Dokumenten erfolgt über die mächtigen T-SQL-Funktionen OPENXML oder OPENJSON.
Zusammenfassung
Diese Vorgehensweise der Extraktion bietet zahlreiche Vorteile. Durch Verwendung eines ETL-Tools wie SSIS, das einen hohen Grad der Parallelisierung in der Datenverarbeitung unterstützt, können die Daten hoch performant in den Tabellen der Schemas E0 und E1 materialisiert werden. Vorsysteme werden minimal belastet und die Daten stehen für eine weitere Verarbeitung, wie zum Beispiel die Extraktion der Attribute aus XML- und JSON-Dokumenten über die T-SQL-Funktionen OPENXML oder OPENJSON in der Schnittstellendatenbank zur Verfügung. Die materialisierten Daten ermöglichen zudem im Fehlerfall eine Analyse der Ursachen.
Technische Transformation
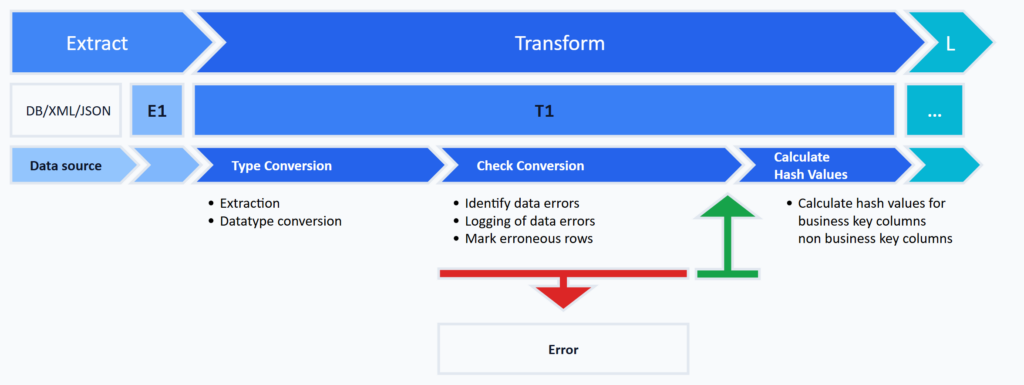
In dem übergeordneten Schritte der Transformation erfolgt nach diesem Design-Pattern die oben beschriebene technische Transformation. Diese umfasst die folgenden Arbeitsschritte:
- Typ-Konvertierung
- Prüfung der technischen Datenqualität
- Protokollierung von Datenfehlern
- Markierung fehlerhafter Datensätze
- Berechnung von Hashwerten
Typ-Konvertierung
Das Ergebnis der technischen Transformation sind typisierte Daten, wie sie im Zielsystem erwartet werden. Die Typisierung kann auf Basis von Metadaten über generische benutzerdefinierte gespeicherte Prozeduren (Stored Procedures) erfolgen und materialisiert die Daten in der Datenbank in Tabellen des Schemas T1.
Je Attribut aus den Tabellen des Schemas E1 werden zwei Spalten in den Tabellen des Schemas T1 bereitgestellt. Die erste Spalte nimmt die extrahierten Daten in dem Datentyp auf, in dem diese in den Tabellen des Schemas E1 gespeichert sind. Die zweite Spalte speichert den typisierten Wert in dem Zieldatentyp, sofern die Daten in den Zieldatentyp konvertiert werden können. Kann ein Wert nicht konvertiert werden, so wird in der jeweils zweiten Spalte ein NULL gespeichert.
Prüfung der technischen Datenqualität
Nach erfolgter Typisierung wird das Ergebnis durch Vergleich der Spaltenpaare auf Probleme bei der Typ-Konvertierung hin geprüft. Da die Typ-Konvertierung ausschließlich einen technischen Charakter hat, wird diese Prüfung hier auch als Prüfung der technischen Datenqualität bezeichnet. Die Fehlerprüfung kann bereits hier auch um die Prüfung einfacher Geschäftslogiken erweitert werden.
Protokollierung von Datenfehlern
Gefundene Datenfehler werden in einer les- und auswertbaren Form in einer Fehlertabelle protokolliert.
Markierung fehlerhafter Datensätze
Enthält ein Datensatz mindestens einen Fehler, wird dieser Datensatz als fehlerhaft markiert, damit diese von der weiteren Verarbeitung ausgeschlossen werden kann. Die Markierung erfolgt in einer Spalte, in der die Anzahl der gefundenen Fehler gespeichert wird. Fehlerfreie Datensätze weisen in dieser Spalte ein NULL auf.
Berechnung von Hashwerten
Der letzte Arbeitsschritt der technischen Transformation ist die Berechnung und Speicherung von zwei Hashwerten je Datensatz. Der erste Hashwert repräsentiert die Felder des fachlichen Schlüssels eines Datensatzes, der zweite Hashwert alle übrigen Felder. Über diese beiden Felder können in dem nachfolgenden Arbeitspaket Historisierung technisch transformierter Daten Änderungsdatensätze identifiziert werden. Hashwerte werden nur für fehlerfreie Datensätze berechnet.
Technologie
Die Konvertierung der extrahierten Werte in die Zieldatentypen, die Prüfung auf Datenfehler, Markierung fehlerhafter Datensätze und Berechnung von Hashwerten kann über generische gespeicherte Prozeduren erledigt werden, die auf der Basis von Metadaten entsprechende dynamische SQL-Statements erstellen. Dieses erfordert einmal Aufwand für die Implementierung solcher Prozeduren. Die genannten Aufgaben können dann durch einfache Prozedur-Aufrufe erledigt werden. Dieses reduziert langfristig den Entwicklungs-Aufwand und unterstützt den Entwickler durch maximale Wiederverwendbarkeit.
Tragweite der Dynamik. Dynamisches SQL fällt im engeren Sinn nur bei der Datenqualitäts-Prüfung an — eine Regel entspricht einer WHERE-Klausel, die zur Laufzeit auf die typisierte Tabelle angewendet wird. Daneben sind die genannten Prozeduren (Typ-Konvertierung, DQ-Prüfung, Markierung, Hashwert-Berechnung) metadaten-getrieben generierbar, weil sie strukturell pro Ziel-Tabelle nach demselben Muster funktionieren. Diese Generierung deckt den Korridor von Extraktion bis zur technischen Historisierung (Schema T2) ab. Ab Schema L1 — der strukturellen Transformation — sind die JOIN-Statements ziel-system-spezifisch und werden manuell entwickelt; ebenso die Historisierungs-Prozeduren für Schema L2 (siehe entsprechende Hinweise weiter unten).
Diese Artikelserie befindet sich derzeit im Aufbau. In einem folgenden Artikel werde ich gespeicherte generische Prozeduren vorstellen, die die genannten Aufgaben übernehmen.
Historisierung der technisch transformierten Daten
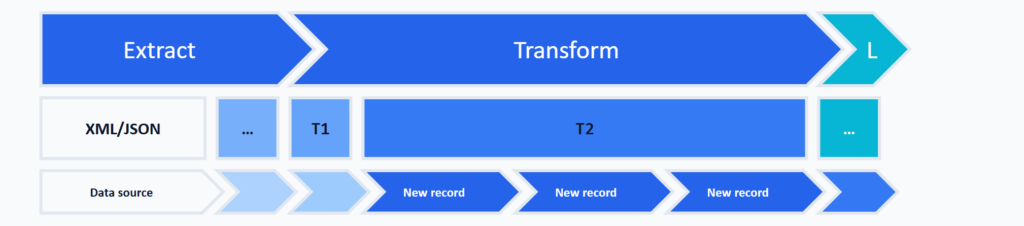
Die Historisierung umfasst die folgenden Arbeitsschritte:
- Historisierung
- Identifikation von Änderungsdaten
- Identifikation über Hashwerte
- Speicherung von Hashwerten
- Übernahme ausschließlich fehlerfreier Datensätze
Historisierung
Historisierung bedeutet, dass gelieferte Daten in einer Datenbank fortgeschrieben werden. Aus dem Bereich des Data-Warehousing sind unter dem Begriff Slowly Changing Dimensions verschiedene Typen der Historisierung bekannt, die festlegen, wie genau Daten fortgeschrieben werden können. Der Begriff Slowly Changing Dimensions ist auch unter der Kurzform SCD bekannt. Klassisch werden nach Ralph Kimball sechs Typen (SCD 1 – SCD 6) beschrieben; manche Quellen ergänzen einen Type 0 (Attribute, die sich nie ändern) und Type 7 (Hybrid aus Surrogat- und Natürlichem Schlüssel). Von diesen Typen werden hier nur zwei erwähnt:
- SCD 1 — beschreibt dem Grunde nach keine echte Historisierung von Daten. Ein bereits zuvor geladener Datensatz wird mit einem geänderten Datensatz lediglich überschrieben. Es werden also immer nur die jeweils letzten Änderungen eines Datensatzes gespeichert.
- SCD 2 — alle Tabellen, in denen Daten historisiert werden, erhalten zwei zusätzliche Spalten ValidFrom und ValidTill, in denen der Gültigkeitszeitraum des Datensatzes angegeben ist. Aktuell gültige Datensätze sind unbegrenzt gültig, was in ValidTill zum Beispiel durch ein NULL angezeigt wird. Werden zu einem aktuellen Datensatz Änderungsdaten geliefert, wird der zuletzt gültige Datensatz in der Spalte ValidTill mit dem Datum, ab dem der Änderungsdatensatz gültig ist, aktualisiert und der Änderungsdatensatz wiederum mit ValidTill = NULL eingefügt.
Eine Historisierung ist optional. Insbesondere bei einem Delta-Load kann sie jedoch hilfreich oder gar erforderlich sein. Nehmen wir an, ein Kunde hat eine neue Bestellung getätigt. Bei einem Delta-Load wird die Bestellung geliefert, aber nicht der Kunde, da sich dieser nicht geändert hat. Eine Auflösung der Fremdschlüsselbeziehung zwischen Bestellung und Kunde kann mit den gelieferten Daten nicht erfolgen. Für eine Auflösung der Fremdschlüsselbeziehung zwischen Bestellung und Kunde sind entweder die Kundendaten aus dem Zielsystem zu extrahieren oder die Kunden sind in der Datenbank zu historisieren, damit bei folgenden Ausführungen des ETL-Prozesses der Kunde verfügbar ist.
Historisierung im Kontext des hier vorgestellten ETL-Prozesses bedeutet, dass nur fehlerfreie und geänderte Datensätze historisiert werden. Die Historisierung kann nach SCD 1 oder SCD 2 erfolgen.
Identifikation von Änderungsdaten
Die Historisierung erfordert, dass wir Änderungsdatensätze in dem Quellsystem und in der Folge auch in den historisierten Tabellen erkennen können. Häufig stellt das Quellsystem keine oder nur unzureichende Informationen darüber bereit, wann ein Datensatz eingefügt, geändert oder gelöscht wurde. Wird zum Beispiel eine CSV-Datei aus einem manuell bearbeiteten EXCEL-Dokument erstellt, können wir immer davon ausgehen, dass keine (belastbaren) Informationen über eine Änderung eines Datensatzes vorliegen. Vor diesem Hintergrund werden nach diesem Design Pattern Änderungsdaten immer über die Daten selbst ermittelt. Hierfür werden die im Zuge der Technische Transformation berechneten Hashwerte verwendet.
Identifikation über Hashwerte
In dem Abschnitt Technische Transformation wurden für fehlerfreie Daten Hashwerte über die Primärschlüsselfelder sowie die nicht Primärschlüsselfelder berechnet. Diese beiden Hashwerte können für die Identifikation von Änderungsdatensätzen verwendet werden. Neue, geänderte und auch gelöschte Datensätze können durch Vergleich der Hashwerte für den fachlichen Schlüssel und der Attribute in den Tabellen den Tabellen, die die extrahierten Daten (Schema T1) enthalten und den historisierten Daten (Schema T2) identifiziert werden:
| Hashwert (fachlicher Schlüssel) | Hashwert (Attribute) | Art der Änderung |
|---|---|---|
| in T1 und T2 vorhanden, gleich | gleich | Keine Änderung |
| in T1 und T2 vorhanden, gleich | ungleich | Datensatz wurde geändert |
| nur in T1 (extrahiert) | — | Neuer Datensatz |
| nur in T2 (historisiert) | — | Datensatz wurde gelöscht |
Speicherung von Hashwerten
Wird ein neuer Datensatz in den historischen Tabellen eingefügt, aktualisiert oder dort als gelöscht markiert, sind dort auch die Hashwerte des neuen, geänderten oder gelöschten Datensatzes zu speichern beziehungsweise zu aktualisieren. Hierdurch wird sichergestellt, dass die dort gespeicherten Hashwerte den Status Quo in den Quellsystemen darstellen und zu jederzeit (in folgenden Ausführungen des ETL-Prozesses) eine Identifikation von Änderungsdatensätzen über die Hashwerte möglich ist.
Übernahme ausschließlich fehlerfreier Datensätze
Die Übernahme eines fehlerhaften Datensatzes und das spätere Laden dieses Datensatzes in das Zielsystem könnte einen Fehler verursachen und ggf. den gesamten ETL-Prozess zum Abbruch bringen. Es werden daher nur fehlerfreie Änderungsdatensätze aus den Tabellen des Schemas T1 in den Tabellen des Schemas T2 gespeichert.
Strukturelle Transformation

Die strukturelle Transformation umfasst die folgenden Arbeitsschritte:
- Strukturelle Transformation und Auflösung von Fremdschlüsselbeziehungen und Lookup-Werten
- Prüfung der strukturellen Datenqualität
- Protokollierung von Datenfehlern
- Markierung fehlerhafter Datensätze
- Berechnung von Hashwerten
Strukturelle Transformation und Auflösung von Fremdschlüsselbeziehungen und Lookup-Werten
Als Ergebnis der strukturellen Transformation liegen die Daten in Tabellenstrukturen vor, wie sie im Zielsystem erwartet werden. Die strukturelle Transformation erfolgt über SQL-Statements mit den erforderlichen JOINs in der FROM-Klausel. Die Entwicklung erfordert hinreichende Kenntnis über die Daten, die Zusammenhänge und vor allem Fremdschlüsselbeziehungen zwischen den Tabellen in einem Quellsystem beziehungsweise den zu integrierenden Quellsystemen.
Neben der eigentlichen strukturellen Transformation der Quelldaten löst die strukturelle Transformation Fremdschlüsselbeziehungen für das Zielsystem auf und ermittelt zu Lookup-Werten den zu speichernden Code. Das Ergebnis der strukturellen Transformation wird in Tabellen des Schemas L1 gespeichert, die bezüglich Tabellenstruktur, Spaltennamen und Datentypen ähnlich zu den Strukturen des Zielsystems sind.
Prüfung der strukturellen Datenqualität
Der letzte Arbeitsschritt der strukturellen Transformation ist die Berechnung von zwei Hashwerten je Datensatz. Der erste Hashwert repräsentiert die Felder des fachlichen Schlüssels eines strukturell transformierten Datensatzes, der zweite Hashwert alle übrigen Attribut-Felder. Über diese beiden Hashwerte können in dem nachfolgenden Arbeitspaket Historisierung strukturell transformierter Daten Änderungsdatensätze leicht identifiziert werden.
Protokollierung von Datenfehlern
Gefundene Datenfehler werden in einer les- und auswertbaren Form in einer Fehlertabelle protokolliert.
Markierung fehlerhafter Datensätze
Enthält ein Datensatz mindestens einen Fehler, wird dieser Datensatz als fehlerhaft markiert, damit diese von der weiteren Verarbeitung ausgeschlossen werden kann. Die Markierung erfolgt in einer Spalte, in der die Anzahl der gefundenen Fehler gespeichert wird. Fehlerfreie Datensätze weisen in dieser Spalte ein NULL auf.
Historisierung der strukturell transformierten Daten
Die Historisierung der strukturell transformierten Daten umfasst die gleichen Arbeitsschritte wie bei der Historisierung der technisch transformierten Daten. Die Historisierung der strukturell transformierten Daten ist ein optionaler Schritt, da diese – wenn die Daten der technischen Transformation historisiert wurden – jederzeit im Zuge der strukturellen Transformation wiederhergestellt werden können.
Die Historisierung der strukturell transformierten Daten aus den Tabellen des Schemas L1 erfolgt in den Tabellen des Schemas L2. Die Vorgehensweise ist identisch zu der Historisierung der Daten aus dem Schema T1 in den Tabellen des Schemas T2. Es werden nur fehlerfreie Änderungsdatensätze aus den Tabellen des Schemas L1 in den Tabellen des Schemas L2 historisiert. Neue, geänderte und gelöschte Datensätze werden zusätzlich mit einem Flag versehen, das anzeigt, dass diese noch in das Zielsystem zu übernehmen sind. Werden auch die Daten des Schemas L2 historisiert, sind diese nie zu löschen und sollten über einen Wartungsprozess gesichert werden. Damit kann jederzeit nachvollzogen werden, wann welcher Datensatz geändert wurde.
Die erforderlichen Prozeduren für die Historisierung von Daten in den Tabellen des Schemas L2 sind manuell zu entwickeln.
Laden

Die transformierten und geprüften Daten aus dem Schema L2 können nun mit einer Technologie der Wahl in das Zielsystem geladen werden. Die zu ladenden Änderungsdaten können über ein Flag, das angibt, ob der Datensatz bereits in das Zielsystem geladen wurde oder nicht, identifiziert werden. Datensätze, die erfolgreich in das Zielsystem geladen wurden, sind entsprechend zu markieren.
FAQ
Die technische Transformation arbeitet pro Datensatz isoliert: Typ-Konvertierung von Eingangswerten in die Zieldatentypen (Text → date, decimal, …) plus eine erste Datenqualitäts-Prüfung auf Wert-Ebene, jeweils ohne Blick auf andere Tabellen. Die strukturelle Transformation braucht dagegen Kontext aus dem Zielsystem — Fremdschlüssel auflösen, Lookup-Werte aus Code-Mappings ableiten — und erfolgt deshalb in einem eigenen Arbeitspaket nach der technischen Transformation. Die Trennung erlaubt, beide Fehler-Klassen getrennt zu protokollieren und zu reparieren.
Materialisierung — das Wegspeichern des Arbeitspaket-Ergebnisses in einer Datenbank-Tabelle — entkoppelt drei Dinge: das Quellsystem wird nur einmal gelesen und arbeitet unbeobachtet vom Folgepaket; jeder Schritt lässt sich nachträglich re-starten, ohne den kompletten ETL-Lauf zu wiederholen; und es entsteht ein nachvollziehbarer Audit-Trail für die Fehlersuche an konkreten Datensätzen. Der Speicher-Overhead ist gegenüber dem Robustheits-Gewinn vernachlässigbar.
Nicht zwingend. Die volle E0/E1/T1/T2/L1/L2-Schichtung lohnt sich vor allem dort, wo Audit-Trail, Wiederanlaufbarkeit pro Arbeitspaket und nachträgliche Fehleranalyse harte Anforderungen sind — klassisch in Migrations- und CRM-Integrations-Projekten mit Datenvolumen im niedrigen bis mittleren Bereich (≤100 Mio. Sätze pro Lauf). Bei großen Datenvolumen oder modernen Plattformen wie Snowflake, Databricks oder BigQuery werden einige Zwischen-Layer oft als Views statt als materialisierte Tabellen umgesetzt — die Architektur-Logik bleibt gleich, der Speicher- und I/O-Aufwand sinkt. Erfahrungswert: T2 und L1 sind die ersten Kandidaten zum Virtualisieren, weil sie sich aus T1 bzw. T2 jederzeit regenerieren lassen.
Historisierung ist immer dann hilfreich, wenn der ETL-Prozess Delta-Loads verarbeitet — also nur die Änderungen seit dem letzten Lauf, nicht den Voll-Snapshot. Bei einem Delta-Load wird der Bestellungs-Datensatz geliefert, aber nicht der dazugehörige Kunde, falls er sich nicht geändert hat; ohne historisierte Kundendaten lässt sich die Fremdschlüssel-Beziehung dann nicht auflösen. Bei vollständigen Snapshot-Loads — wo jeder Lauf das gesamte Quellsystem zieht — ist SCD optional und meist überflüssig.
Die zentralen Konzepte des Pattern — Arbeitspakete, Schema-Schichtung E0–L2, Datenqualität an den Grenzen, Hash-basierte SCD — sind nicht an SQL Server gebunden und lassen sich in jeder relationalen Datenbank umsetzen. Der hier vorgestellte Code ist allerdings durchgängig T-SQL-/SQL-Server-zentriert (SSIS, OPENXML, OPENJSON, HASHBYTES, metadaten-getriebene SP-Generierung). Für Postgres sind die wichtigsten Pendants: xmltable() für XML, jsonb_to_recordset() bzw. JSON_TABLE (ab Postgres 17) für JSON, digest(…, 'sha256') aus pgcrypto für Hashes. Die strukturelle Anpassung kann tiefer gehen als nur Funktionsnamen — etwa lässt sich das E0/E1-Splitting für XML/JSON in Postgres oft einsparen, weil xmltable() direkt aus dem Source-Read heraus extrahiert.
Es gibt deutliche Verwandtschaften — fachlicher Schlüssel, Hash-basierte Delta-Erkennung, Schichten-Trennung Raw / Cleansed / Business, Auditierbarkeit. Wer Data Vault kennt, wird E1/T2 als „Raw + Hub/Satellite-äquivalent“ und L1/L2 als „Business-Vault“ interpretieren können. Das hier vorgestellte Pattern ist allerdings leichter: keine strikte Hub/Link/Satellite-Trennung, keine Pflicht zur Insert-Only-Historie, keine Raw-Vault-vs-Business-Vault-Trennung als Architektur-Dogma. Für klassische Migrations- und CRM-Integrations-Projekte mit Audit-Anforderung ist die Vereinfachung pragmatisch; für reine DWH-Bewirtschaftung mit Multi-Source-Integration lohnt sich ein Blick auf Data Vault 2.0.
Verwandte Artikel
- Datenqualität in einem ETL-Prozess — Serien-Wurzel.
- Design Pattern // Protokollierung eines ETL-Prozesses mit SQL — Cluster-Schwester zur Protokollierungs-Schicht.
- Design Pattern // Sichere Typ-Konvertierung mit T-SQL —
fn_try_convert_*-UDFs für die technische Transformation. - Datenqualität // Grundlagen der Typ-Konvertierung mit T-SQL — Grundlagen-Artikel zu
TRY_CONVERT. - ETL vs. ELT — woran du erkennst, welches Muster du wirklich gebaut hast — ordnet die hier vorgestellte Architektur als persistent-staging-ELT ein.
- Datenqualität mit SQL prüfen — die generischen Prüfroutinen, die schlechte Daten in der Staging-Schicht aufspüren, bevor das Laden bricht.