Sind in einem ETL-Prozess Daten aus Text-Dateien zu extrahieren, ist grundsätzlich Vorsicht geboten. Text-Dateien definieren an sich bereits eine Schnittstelle zu einem Vorsystem. Zwischen der die Daten liefernden Stelle und dem ETL-Prozess muss es daher eine Vereinbarung geben, welche Daten in welchem Format geliefert werden, in welchem Format sie bereitgestellt werden und welche Wertebereiche zulässig sind. Die Erfahrung aus der Praxis zeigt, dass die gelieferten Daten trotz entsprechender Vereinbarungen oft nicht dieser Vereinbarung entsprechen oder nicht in ausreichender Qualität bereitgestellt werden.
Daten die als Text geliefert werden, sind in einem ETL-Prozess im ersten Schritt in die jeweiligen Zieldatentypen zu konvertieren. Die Typ-Konvertierung ist ein heikler Prozess, da dieser – wenn die Typ-Konvertierung keine explizite Fehlerbehandlung implementiert – zu einem Abbruch eines ETL-Prozesses führen kann. Eine umfassende Prüfung der gelieferten Daten ist darüber hinaus zwingend notwendig.
Dieser Artikel beschreibt eine robuste Systematik für die Typ-Konvertierung, über die sämtliche Probleme bei der Typ-Konvertierung einzelner Werte identifiziert werden können und den Konvertierungsprozess trotz möglicher vorhandener Probleme nicht zu einem Abbruch führt. Die Systematik basiert im Wesentlichen auf drei Paradigmen:
- Die Konvertierungsfunktion gibt ein NULL zurück, wenn der Eingangswert nicht in den Zieldatentyp konvertiert werden kann
- In dem ETL-Prozess werden in einer Tabelle sowohl der Eingangswert, als auch der konvertierte Ausgangswert gespeichert
- Durch den Vergleich des Eingangswertes mit dem Ausgangswert kann ein Fehler bei der Typ-Konvertierung identifiziert werden
SQL Server stellt mit der BuiltIn Funktion TRY_CONVERT eine Funktion zur Verfügung, mit der die erste Forderung erfüllt wird. Die Funktion TRY_CONVERT gibt im Fehlerfall ein NULL zurück. Alleine die Anwendung dieser Funktion stellt aber noch nicht die korrekte Konvertierung eines Eingangswertes sicher. Um eine sichere Konvertierung eines Eingangswertes in den Datentyp des Ausgangswertes sicherzustellen, ist es erforderlich, die Besonderheiten der Typ-Konvertierung in Abhängigkeit von dem Zieldatentyp zu kennen. Bei einigen Datentypen kann darüber hinaus die Funktion nicht angewendet werden. Eine Ja/Nein-Information kann zum Beispiel in Form eines Textes geleifert werden: J, N, Y, N, Yes, No, … Ähnliches gilt auch für ein Datum mit oder ohne Uhrzeit. Für diese beiden Datentypen sind benutzerdefinierte gespeicherte Funktionen zu schreiben, die die Konvertierung gemäß des ersten Paradigmas erledigen.
Eine robuste und sichere Typ-Konvertierung ist insbesondere in Datenmigrationsprojekten, bei den die zu verarbeitenden Daten in Form von Dateien (Excel, CSV, XML JSON, etc.) geliefert werden.
In diesem Artikel werden zunächst die Grundlagen der sicheren Typ-Konvertierung und die Identifikation von Problemen bei der Konvertierung gelegt, sowie die Besonderheiten der Typ-Konvertierung in Abhängigkeit von dem Zieldatentyp untersucht und beschrieben.
Inhalt
- Eingangs- und Ausgangswerte
- Materialisierung der extrahierten Daten
- Identifikation von Komvertierungs-Fehlern
- Konvertierung in Abhängigkeit von dem Ziel-Datentyp
Eingangs- und Ausgangswerte
Als Eingangswerte werden Daten bezeichnet, die extrahiert und in einer Datenbank in Tabellen und Spalten mit dem Datentyp nvarchar gespeichert wurden. Als Ausgangswerte werden Daten bezeichnet, die aus den Eingangswerten in den Zieldatentypen konvertiert wurden. Zu jedem zu verarbeitenden Eingangswert gibt es auch einen Ausgangswert.
Materialisierung der extrahierten Daten
ETL-Tools wie SSIS verleiten dazu, die Datenverarbeitung komplett in den Arbeitsspeicher zu verlegen und ein Zwischenergebnis nicht in einer Datenbank zu speichern. Bei dieser Vorgehensweise ist es erforderlich, sämtliche Aufgaben in SSIS in einem Controlflow zu entwickeln: die Extraktion, die Typ-Konvertierung und die Identifikation von Konvertierungsproblemen. Können Werte nicht konvertiert werden, ist eine umfangreiche Behandlung und ggf. Protokollierung von Datenfehlern erforderlich. Enthält ein Datensatz mehrere Fehler, wird gegebenenfalls nur der erste gefunden Fehler behandelt und protokolliert. Hand auf’s Herz! Wer hat das schon mal in SSIS gemacht!? Fehlerhafte Datensätze werden allenfalls in eine Textdatei ausgeleitet, die sich nie jemand anschaut. So mächtig ETL-Tools auch sind, in der Realität wird eine umfassende Fehlerbehandlung bei der Typ-Konvertierung nicht (oft) gemacht. ETL-Tools können in diesem Punkt ein Pain in the Ass sein.
Besser ist es, die Arbeitsschritte strikt von einander zu trennen und die Zwischenergebnisse in einer Datenbank zu materialisieren. Für nichts anderes steht das Akronym ETL. Die zu verarbeitenden Daten werden zunächst in einer Datenbank extrahiert. Anschließend ist eine fehlerunanfällige und robuste Typ-Konvertierung durchzuführen. Im letzten Schritt können fehlerfreie Daten identifiziert und weiterverarbeitet werden:
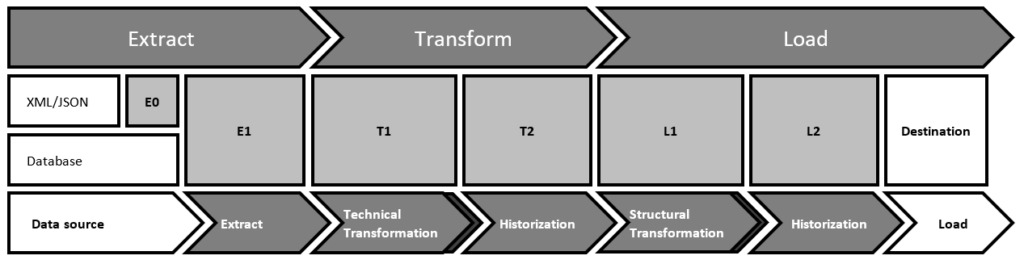
Diese Abbildung zeigt einen ETL-Prozess, in dem für jede durchzuführenden Aufgabe ein separates Datenbankschema erzeugt wird:
| Schema | Bedeutung |
|---|---|
| E0 | Speicherung von XML- und JSON-Dateien in der Datenbank |
| E1 | Extraktion der Werte aus den Textdateien |
| T1 | Typ-Konvertierung der extrahierten Werte |
| T2 | Historisierung von fehlerfrei konvertierten Datensätzen |
| L1 | Strukturelle Transformation in Richtung Zielsystem |
| L2 | Speicherung fehlerfreier und strukturell transformierter Daten |
Konzentrieren wird uns auf die Schemas E1 und T1.
Schema E1
Extrahierte Daten werden in Tabellen des Schemas E1 in Spalten mit dem Datentyp nvarchar gespeichert. Gegebenenfalls ist die Länge der Textfelder nicht zu beschränken. Die Länge der Text-Felder ist jedenfalls so zu wählen, dass eine vollständige Extraktion aller Daten sichergestellt ist. Die Extraktion der Daten kann dann nur bei Problemen mit der Infrastruktur zu einem Fehler führen. Die extrahierten Daten werden auch als Eingangswerte bezeichnet.
Schema T1
Zu jeder Tabelle aus dem Schema E1 existiert eine gleichnamige Tabelle in dem Schema T1. In den Tabellen des Schemas T1 werden die Spalten der Eingangswerte in dem Datentyp nvarchar übernommen und zusätzlich eine zweite Spalte je Eingangswert eingefügt, dieses Mal aber mit dem Datentyp des Zielsystems. Aus pragmatischen Gründen erhalten diese Spaltenpaare den gleichen Spaltennamen, wobei die Spalten, die den Eingangswert aufnehmen den Suffix _E1 erhalten. Ein Beispiel…
CREATE TABLE [T1].[Table]
(
[Id] int IDENTITY(1,1) NOT NULL
,[PK_E1] nvarchar(256) NULL
,[PK] int NULL
,[Text_E1] nvarchar(256) NULL
,[Text] nvarchar(3) NULL
,[Integer_E1] nvarchar(256) NULL
,[Integer] int NULL
,[Date_E1] nvarchar(256) NULL
,[Date] datetime NULL
);
In der Tabelle [T1].[Table] sind alle Spalten bis auf die Spalte [Id] als Nullable deklariert. Damit können sowohl die Eingangswerte aus einer Tabelle [E1].[Table] als auch die konvertierten Ausgangswerte – auch in Anwesenheit von Konvertierungsproblemen – gespeichert werden. Voraussetzung ist jedoch, dass alle Konvertierungsfunktionen im Fehlerfall ein NULL zurückgeben.
Identifikation von Konvertierungs-Fehlern
Schauen wir und ein Datenbeispiel für die oben genannte Tabelle [T1].[Table] an.
| Id | PK_E1 | PK | Text_E1 | Text | Integer_E1 | Integer | Date_E1 | Date |
|---|---|---|---|---|---|---|---|---|
| 1 | 1023 | 1023 | S01 | S01 | 25.5 | NULL | 20240218 | 18.02.2024 |
| 2 | 1024 | 1024 | S022 | S02 | 87 | 87 | 20240230 | NULL |
| 3 | 1025X | NULL | S03 | S03 | 65 | 65 | 20240219 | 19.02.2024 |
Probleme bei der Konvertierung von Eingangswerten in den Datentyp des Ausgangswertes können über einfache WHERE-Klausel identifiziert werden. Für Ausgangswerten von dem allgemeinen Datentyp Kein Text identifizieren die folgenden WHERE-Klauseln Probleme bei der Typ-Konvertierung:
WHERE [PK_E1] IS NOT NULL AND [PK] IS NULL WHERE [Integer_E1] IS NOT NULL AND [Integer] IS NULL WHERE [Date_E1] IS NOT NULL AND [Date] IS NULL
Für Ausgangswerte, die von dem allgemeinen Datentyp Text sind, kann auf Ungleichheit abgefragt werden, um zu lange Texte und damit Probleme zu identifizieren:
WHERE [Text_E1] <> [Text]
Konvertierung in Abhängigkeit von dem Ziel-Datentyp
Nun stellt SQL Server Funktionen für die Konvertierung von Daten in einen Zieldatentyp zur Verfügung. Auch ich habe diese in der Vergangenheit einfach angewendet, ohne genau zu untersuchen, wie diese tatsächlich arbeiten. Bei genauerer Untersuchung habe ich festgestellt, dass zum Beispiel die das Ergebnis der Konvertierung einer leeren Zeichenfolge die Zahl 0 ist:
SELECT TRY_CONVERT(int, N'' ) -- > 0 SELECT TRY_CONVERT(int, N' ') -- > 0
Das kann fachlich korrekt sein. Aus Sicht des Datenbankentwickler jedoch wird kein Wert geliefert. Der Wert ist unbekannt und dem zur Folge wäre ein NULL das korrekte Ergebnis der Konvertierung. Derart gibt es einige Feinheiten, die bei einer gesicherten Typ-Konvertierung zu berücksichtigen sind.
In den folgenden verlinkten Artikeln wird je Datentyp hergeleitet, wie ein Eingangswert gesichert und fachlich korrekt in die Datentypen der Ausgangswerte zu konvertieren sind. Die sichere Typ-Konvertierung wird für die folgenden Datentypen hergeleitet:
| Datentyp | Wertebereich | Byte |
|---|---|---|
| char | Zeichenfolge mit fester Länge und 1 Byte pro Zeichen | n |
| nchar | Zeichenfolge mit fester Länge und 2 Byte pro Zeichen | 2 * n |
| varchar | Zeichenfolge mit variabler Länge und 1 Byte pro Zeichen | variabel |
| nvarchar | Zeichenfolge mit variabler Länge und 2 Byte pro Zeichen | variabel |
| bigint | -9.223.372.036.854.775.808 bis 9.223.372.036.854.775.807 | 8 |
| int | -2.147.483.648 bis 2.147.483.647 | 4 |
| smallint | –32.768 bis 32.767 | 2 |
| tinyint | 0 bis 255 | 1 |
| numeric [(p [, s])] decimal[(p [, s])] | – 10^38 +1 bis 10^38 – 1 Funktional sind beide Datentypen identisch p = Anzahl der Dezimalstellen (Vor- und Nachkommastellen) s = Anzahl der Nachkommastellen | 5-17 |
| money smallmoney | Aus Gründen der Genauigkeit und des besonderen Verhaltens von money Werten bei Berechnungen wird empfohlen ersatzweise den Datentyp decimal zu verwenden. | 8 4 |
| float[n] real | n = Anzahl der Bits, die zum Speichern der Mantisse verwendet wird (1-53) | 8 |
| Synonym für float(24) | 4 | |
| bit | 0 oder 1 | 1 |
| date | Wertebereich = 01.01.1753 und dem 31.12.9999 | 3 |
| datetime | Wertebereich = 01.01.1753 und dem 31.12.9999 mit Uhrzeit Genauigkeit in Sekundenbruchteilen = 3 | 8 |
| datetime2(n) | Wertebereich = 01.01.0001 bis 31.12.9999 mit Uhrzeit n = Genauigkeit in Sekundenbruchteilen | 6-8 |
| time(n) | Wertebereich = 00:00:00 bis 23:59:59.9999999 mit Uhrzeit n = Genauigkeit in Sekundenbruchteilen | 5 |
in den folgenden Artikeln dieser Artikelserie wird die sichere Typ-Konvertierung in Abhängigkeit von dem Datentyp des Ausgangswertes beschrieben.
Kritische Würdigung der Systematik
Dieser Artikel hat die grundlegende Systematik einer sicheren Typ-Konvertierung aufgezeigt. Die Implementierung dieser Systematik in einem ETL-Prozess erscheint auf den ersten Blick aufwändig. SQL Statements, die Daten aus den Tabellen des Schemas E1 lesen und typisiert in den Tabellen des Schemas T1 speichern, können bei Tabellen mit vielen Spalten komplex werden.
Es bietet sich daher an, darüber nachzudenken, diese Aufgabe einmalig über eine generische gespeicherte Prozedur zu entwickeln. Eine gespeicherte Prozedur, die auf der Basis von Metadaten, die die Tabellenstrukturen der Tabellen in dem Schema T1 beschreiben, dynamisch ein SQL Statement erstellt, das die Konvertierung übernimmt, reduziert den Entwicklungsaufwand für die Konvertierung der Daten einer Tabelle im Wesentlichen auf eine Zeile Code.
Die Entwicklung einer solchen Prozedur wird demnächst in einem separaten Artikel beschrieben.
Verwandte Artikel
- Grundlagen der Typ-Konvertierung mit T-SQL
- Datenqualität // Konvertierung nach bigint, int, smallint, tinyint
- Datenqualität // Konvertierung nach decimal oder numeric
- Datenqualität // Konvertierung nach float, real
- char, nchar, varchar, nvarchar
- bit
- date, datetime, datetime2(n), time(n)